논문 제목: Learning Transferable Visual Models From Natural Language Supervision
출판 학회: ICML? Open AI 논문
출판 연도: 2021년
Abstract
기존의 computer vision: 추가 라벨링 데이터가 필요한 supervised learning 형태
대안으로, 이미지에 대한 raw text로부터 다이렉트하게 학습하는 것이 제안되었다.
본 논문에서는, 어떤 캡션이 어떤 이미지와 짝을 이루는지를 예측하는 단순한 사전학습 과제가, 이미지 표현을 스크래치부터 학습하기 위한 효율적인 방법을 보여준다.
사전학습 시에, 400만개의 (이미지, 텍스트) pair 데이터셋을 사용했고, 사전학습 이후에는 학습된 visual concept들을 지칭하는데 자연어를 사용하고, 이로써 모델을 downstream tasks에 zero-shot으로 transfer할 수 있다.
30개의 다른 computer vision datasets으로 벤치마킹함으로써 성능을 검증하였다.
1. Introduction and Motivating Work
<raw text로부터 다이렉트하게 학습하는 사전학습 방법> - NLP
"text-to-text" 방법의 발전은 task-agnostic(테스크에 종속되지않는) 아키텍쳐의 downstream datasets으로의 zero-shot transfer가 가능하게 하였다. 즉, 특정 데이터셋 별로 specialized output heads가 더 이상 필요하지 않게 되었다.
ex) GPT-3: 추가적인, 특정한 학습 데이터 없이 다양한 task에 적용 가능
⇒ NLP 분야에서는, high-quality crowd-labeled NLP 데이터셋보다, web-scale text collections을 활용한 사전학습이 더 풍부한 supervision 제공한다는 것이 확인되었다.
<그렇다면 CV 분야에서는?>
여전히 ImageNet 과 같은, crowd-labeled datset으로 사전학습을 하는 것이 일반적이다.
따라서, 본 논문에서는 web text로부터 다이렉트하게 학습하는 scalable pre-training 방법이 computer vision에서도 유사한 breakthrough를 가져올 수 있을지를 질문하고 있다...
❓web image로부터 다이렉트하게 학습하는 방법은 없는가? 해상도나 그런것들이 다 달라서?캡션이 있어야하기 때문에?
<기존 연구 정리>
Mori et al. (1999) - content based image retrieval 개선: 이미지와 짝지어진 텍스트 문서 속 명사, 형용사 예측 모델 학습
Quattoni et al. (2007) - 이미지 캡션 속 단어를 예측하도록 학습된 분류기의 weight space에서 manifold learning을 적용해, 더 데이터 효율적인 image representation 학습 가능성을 보여줌.
cf) manifold learning: 복잡한 고차원 데이터 안에 숨어 있는 저차원 구조(=manifold)를 찾아내는 기계학습 기법
Srivastava & Salakhutdinov (2012) - low-level image, text tag 특징 위에 multimodal Deep Boltzmann Machines를 학습시켜 deep representation learning
cf) low-level image: color, intensity, edge, texture와 같이 픽셀 단위에서 직접 뽑아낸 단순한 정보
Joulin et al. (2016) - CNN을 이미지 캡션 속 단어 예측에 활용 → 유용한 image representation을 학습할 수 있음을 입증; YFCC100M dataset의 title, description, hashtag을 bag-of-words multi-label classification으로 변환하여 AlexNet으로 사전학습 ⇒ 결과적으로 ImageNet 기반 사전학습과 유사한 transfer 성능 달성
cf) bag-of-words: 문장을 “단어 순서”는 무시하고, 단어가 등장했는지 여부나 빈도수만 세는 방식
Li et al. (2017) - 단어뿐만 아니라 phase n-grams까지 예측하도록 확장 ; 학습된 visual n-grams 사전을 활용해 target class 점수를 계산해서 가장 높은 점수를 예측 → zero-shot transfer 가능성 입증
cf) n-grams: 연속된 n개의 단어 묶음
VirTex (Desai & Johnson, 2020) - transformer-based language modeling 활용해서 텍스트로부터 image representations 학습 가능성 제시
ICMLM (Sariyildiz et al., 2020) - masked language modeling 접근을 이미지-텍스트 학습에 적용
ConVIRT (Zhang et al., 2020) - contrastive objectives 사용하여 이미지와 텍스트로부터 강력한 표현 학습
2. Approach
2.1. Natural Language Supervision
Zhang et al. (2020), Gomez et al. (2017), Joulin et al. (2016), Desai&Johnson (2020)
- text-image pair에서 visual representation 학습
- unsupervised, self-supervised, weakly supervised, supervised 방식으로 각각 접근
공통점은 'natural language supervsion'으로부터 학습했다는 것.
이러한 방식으로 했을 때의 장점
1. much easier to scale natural langauge supervision
2. 인터넷 상에 존재하는 많은 양의 text로부터 학습 가능
3. 단순히 representation만 학습하는게 아니라, 유연한 zero-shot transfer가 가능하도록 language에 representation을 연결
2.2. Creating a Sufficiently Large Dataset
기존 연구에서 많이 쓰이는 데이터셋
1. MS-COCO
2. Visual Genome
3. YFCC100M
CLIP 논문에서는 인터넷에 공개된 다양한 4억개의 (image, text) pairs로 구성된 새로운 데이터셋을 구성.
2.3. Selecting an Efficient Pre-Training Method

initial approach: image CNN + text transformer
-> 63million parameter transformer language model은 bag-of-words에 비해 매우 느림
최근 연구: 이미지에서 contrastive representation learning, contrastive objectives가 더 나은 표현을 학습; 이미지 생성 모델이 높은 퀄리티의 이미지 표현을 학습할 수 있지만, contrastive model에 비해서 많은 계산량이 요구된다.
=> 단어-이미지 매칭 대신 텍스트 전체-이미지 매칭을 예측하는 과제를 설정하고, contrastive learning 목표로 바꿨더니 ImageNet zero-shot 전이 효율이 4배 개선되었다.
N개의 (이미지, 텍스트) 페어로 이루어진 배치가 주어질 때, CLIP은 NxN개의 가능한 (이미지, 텍스트) 페어를 예측하도록 train되었다.
Image와 text간의 cosine similarity를 최대화하는 방식으로 image encoder, text encoder를 jointly training

이러한 유사도 점수에 대해 symmetric cross entropy loss을 최적화한다.
사전학습 데이터셋이 매우 컸기 때문에, overfitting이 큰 문제가 되지 않았다.
CLIP을 학습할 때 이미지 인코더를 ImageNet 가중치로 초기화하거나 텍스트 인코더를 사전학습된 가중치로 초기화하지 않고, 완전히 처음부터 학습한다. 또한, 표현과 대조 임베딩 공간 사이의 비선형 projection을 사용하지 않고, 단순히 선형 projection만을 사용해 각 인코더의 표현을 다중 모달 임베딩 공간으로 매핑한다.
또한 이전 연구에서 사용한 텍스트 변환 함수 tᵤ (텍스트에서 문장을 균등 확률로 하나 샘플링)를 제거했는데, 이는 CLIP의 사전학습 데이터셋의 많은 (이미지, 텍스트) 쌍이 단일 문장으로만 구성되어 있기 때문이다. 이미지 변환 함수 tᵥ 또한 단순화하여, 크기 조정된 이미지에서 임의의 정사각형 크롭만을 데이터 증강으로 사용했다.
2.4 Choosing and Scaling a Model
이미지 인코더를 위해 두 가지 다른 아키텍처를 고려했다.
첫 번째로, 널리 사용되고 성능이 입증된 ResNet-50을 기본 아키텍처로 사용하였다.
global average pooling 레이어를 attention pooling 메커니즘으로 교체했다. (transformer스타일)
두 번째 아키텍처로는 최근 제안된 Vision Transformer를 실험하였다.
텍스트 인코더는 아키텍처 수정을 반영한 Transformer이다. 기본 크기는 12 layers, 512 차원(hidden size), 8 어텐션 헤드를 가진 6,300만 파라미터 모델이다. 트랜스포머는 49,152개 단어 집합 크기의 소문자화된 BPE(byte pair encoding) 표현을 입력으로 받는다. 계산 효율성을 위해 최대 시퀀스 길이는 76으로 제한했다. 텍스트 시퀀스는 [SOS], [EOS] 토큰으로 감싸고, [EOS] 위치에서 트랜스포머 최상위 층의 출력을 텍스트 표현으로 사용한다. 이 표현은 레이어 정규화를 거쳐 선형 사영되어 다중 모달 임베딩 공간으로 매핑된다. 텍스트 인코더에는 마스크드 자기어텐션이 사용되었는데, 이는 사전학습된 언어 모델 초기화나 언어 모델링을 보조 목표로 추가할 가능성을 열어두기 위함이며, 이는 향후 연구로 남겨두었다.
이전의 컴퓨터 비전 연구는 보통 너비(width)나 깊이(depth)만 단독으로 확장하는 방식이 많았지만, ResNet 이미지 인코더의 경우 Tan & Le(2019)의 접근 방식을 차용했다. 추가 계산 자원을 단일 차원에만 늘리는 것보다 너비·깊이·해상도에 균등하게 분배했다. 텍스트 인코더의 경우에는 ResNet 너비 증가에 비례해 너비만 확장했고, 깊이는 늘리지 않았다. 이는 CLIP의 성능이 텍스트 인코더 용량에는 상대적으로 덜 민감했기 때문이다.
2.5. Training
총 5개의 ResNet과 3개의 Vision Transformer(ViT)를 학습했다.
- ResNet 계열: ResNet-50, ResNet-101, 그리고 EfficientNet 스타일 모델 확장을 적용한 3개(RN50x4, RN50x16, RN50x64)로, 각각 ResNet-50 대비 약 4배, 16배, 64배의 연산량을 사용한다.
- Vision Transformer 계열: ViT-B/32, ViT-B/16, ViT-L/14.
32 epoch
Adam optimizer, 모든 가중치에 decoupled weight decay 정규화
learning rate: cosine schedule
하이퍼파라미터는 ResNet-50을 1 epoch 학습한 기준으로 grid search, random search, 수동 튜닝을 혼합하여 설정한 뒤, 더 큰 모델에 대해서는 계산 제약 때문에 heuristic하게 조정했다. 학습 가능한 온도 매개변수 τ는 0.07에 해당하는 값으로 초기화했고, logits이 100 이상으로 스케일되는 것을 방지하기 위해 클리핑했다. 이는 학습 불안정성을 막기 위해 필요했다.
매우 큰 미니배치 크기(32,768)를 사용했다. 학습 가속과 메모리 절약을 위해 혼합 정밀도(mixed precision; Micikevicius et al., 2017)를 적용했다. 추가 메모리 절약을 위해 gradient checkpointing(Griewank & Walther, 2000; Chen et al., 2016), half-precision Adam 통계(Dhariwal et al., 2020), half-precision 확률적 반올림(stochastic rounding)이 적용된 텍스트 인코더 가중치를 사용했다. 임베딩 유사도 계산도 GPU별로 부분 샤딩하여 로컬 배치에 필요한 쌍별 유사도만 계산했다.
가장 큰 ResNet 모델(RN50x64)은 592개의 V100 GPU에서 18일간 학습되었고, 가장 큰 Vision Transformer는 256개의 V100 GPU에서 12일이 걸렸다. ViT-L/14의 경우 FixRes(Touvron et al., 2019)와 유사하게 성능 향상을 위해 해상도 336px에서 한 epoch을 추가 사전학습했으며, 이 모델을 ViT-L/14@336px으로 표기한다.
3. Experiments
3.1. Zero-shot Transfer


transformer-based language model이 weak at zero-shot ImageNet classification (BoW prediction(제일 기본)보다 정확도가 낮음)

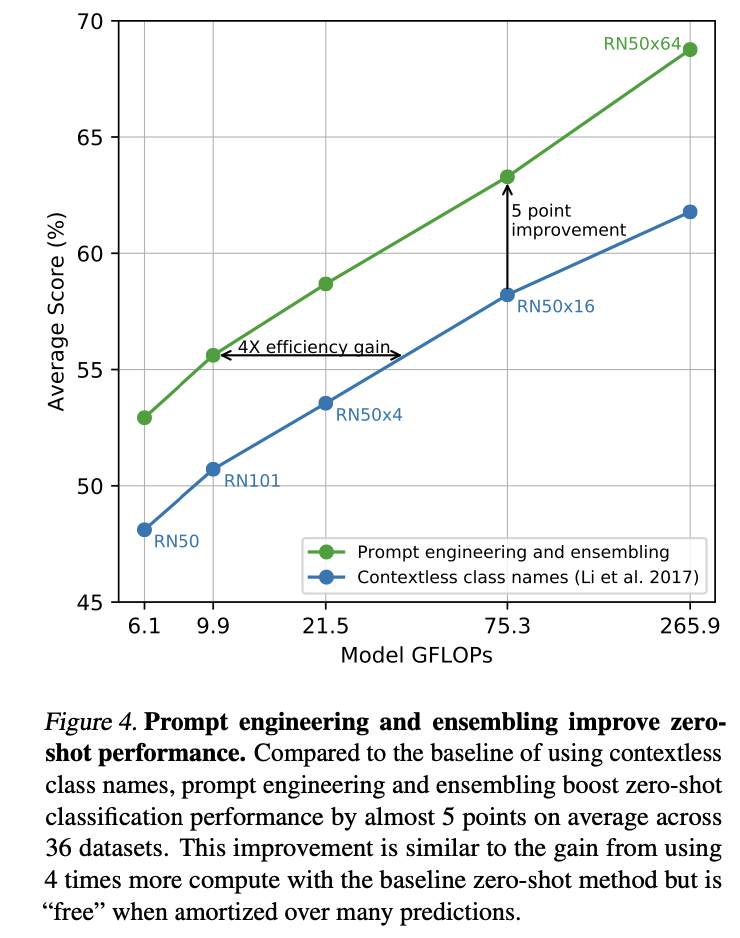
프롬프트 엔지니어링 + 앙상블이 zero-shot 성능을 향상시켰다.



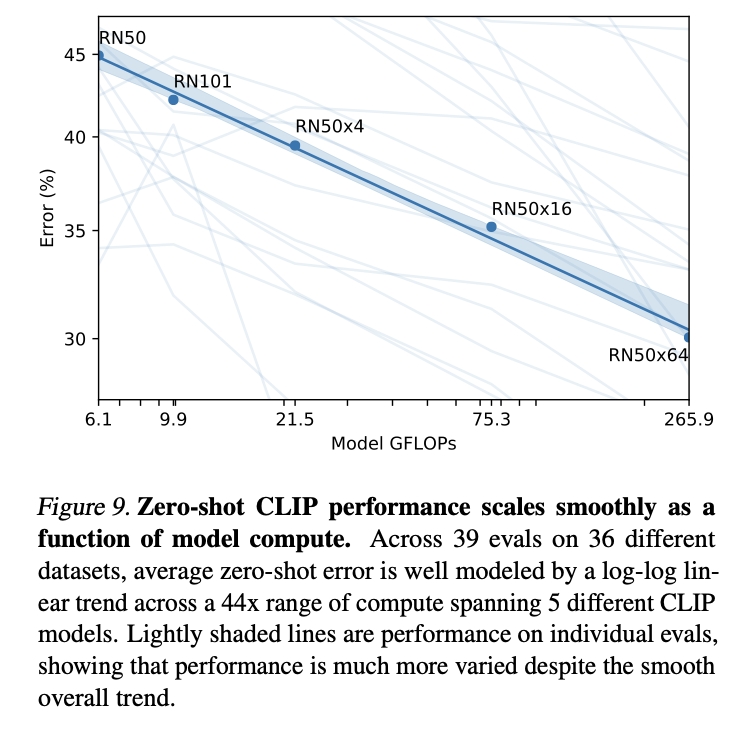


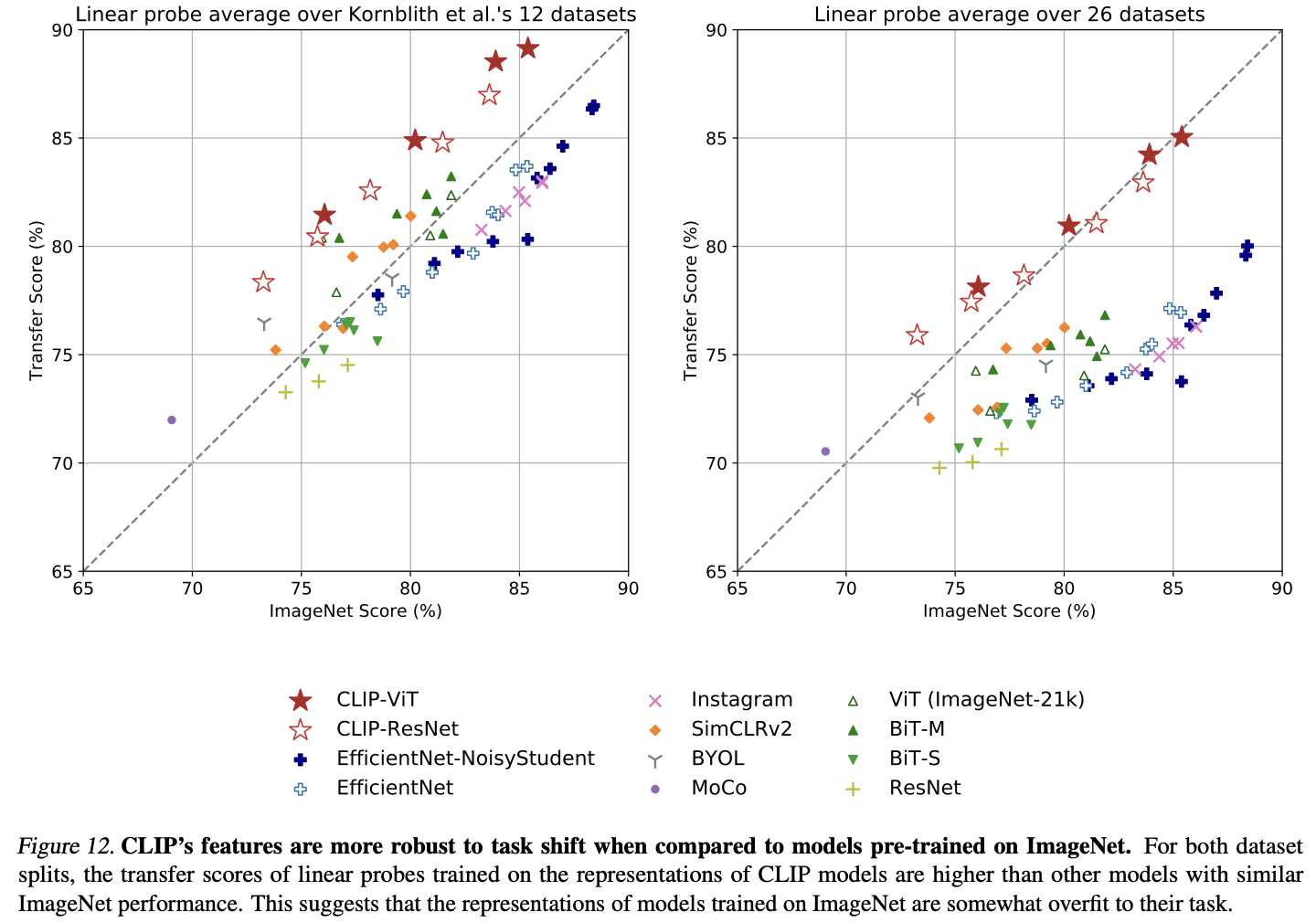


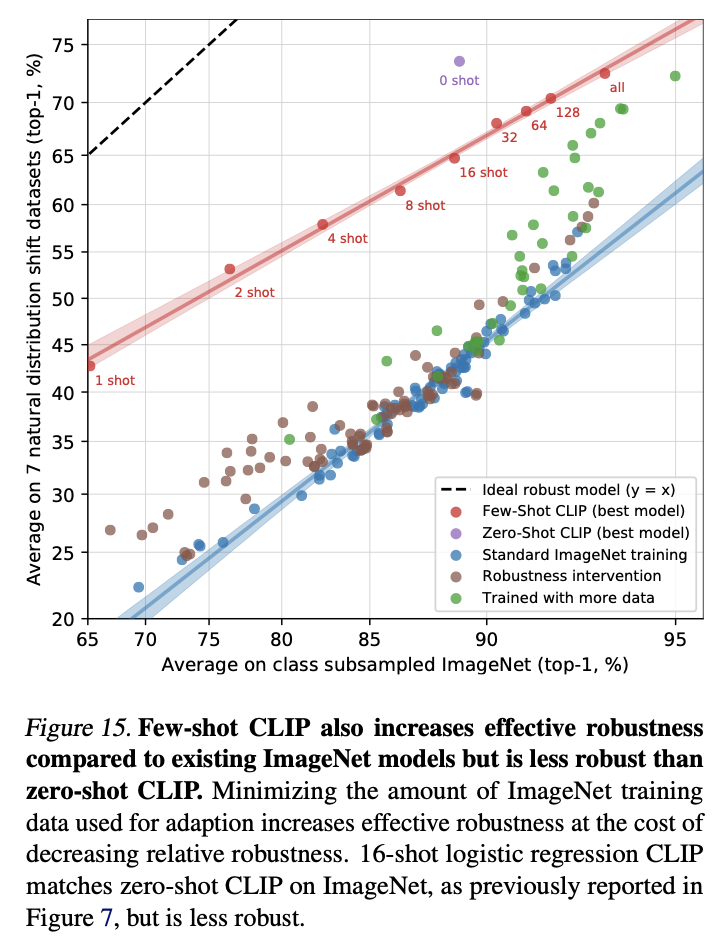
'deep learning' 카테고리의 다른 글
| [논문 공부] Generative Adversarial Nets (0) | 2025.11.03 |
|---|---|
| GPT 구조 이해하기 (0) | 2025.08.11 |
| BERT 구조 이해하기 (2) | 2025.08.08 |
| [논문 리뷰] Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps (0) | 2025.05.10 |


