*논문 정보
제목: Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
저자: Karen Simonyan, Andrea Vedaldi, Andrew Zisserman
연도: 2014
학회명: ICLR
카테고리: XAI
*용어
saliency map: 컴퓨터 비전 분야에서 모델이 어떤 입력의 어떤 부분을 중요하게 생각했는지를 시각화한 지도 → 모델의 설명 가능성을 높이므로 XAI 기법에 해당
deconvolutional networks: 이미지 복원/생성하는 네트워크(CNN과 반대방향). 즉, high level feature → 원래 이미지처럼 복원
Abstract
이 논문은 deep Convolutional networks(ConvNets)를 활용한 image classification model의 visualization을 다룬다.
입력 이미지에 대한 class score의 gradient를 계산하는 두 가지 visualization 기법을 고려한다.
1. class score를 극대화하는 image 생성: ConvNet에 의해 capture된 클래스 개념을 시각화
2. 주어진 이미지, 클래스에 대한 class saliency map 계산
→ 이러한 map이 classification ConvNets를 활용한 weakly supervised object segmentation에 사용될 수 있음을 보인다.
또한, gradient-based ConvNet visualisation 기법과 deconvolutional networks간의 커넥션을 확립한다.
1. Introduction
ConvNets이 대규모 이미지 인식에 널리 사용되면서, 이러한 deep model이 시각적 외형의 어떤 측면을 capture, 즉 학습했는지를 이해하는 것이 중요한 문제가 되었다.
선행 연구를 살펴보면, Erhan 등은 gradient ascent 최적화를 수행해 관심있는 뉴런 활성을 최대화하는 입력 이미지를 찾아 deep model을 시각화하였다. 이 방법은 Deep Belief Network (DBN)과 같은 unsupervised deep architecture의 hidden feature layers를 시각화하는데 사용되었고, 이후 Le 등은 이를 deep unsupervised auto-encoder가 학습한 class model을 시각화하는데 활용하였다. 최근에는 Zeiler 등이 ConvNet visualisation 문제를 다루면서 각 레이어의 출력을 통해 입력을 복원하는 Deconvolutional Network(DeconvNet) 구조를 제안하였다.
본 논문에서는, ImageNet으로 학습된 deep image classification ConvNets의 visualisation을 다루며, 3가지 기여를 보이고자 한다.
1. ConvNet classification models의 납득가능한 시각화가 입력 이미지의 numerical optimisation 방식을 통해 얻어질 수 있음을 보인다. (Erhan의 방법 활용; Erhan 논문과 달리 이 논문은 supervised model을 사용하기 때문에 어떤 뉴런을 시각화할 지 알고 있음)
2. classification ConvNet을 한 번 back-propagation을 진행함을 통해 주어진 이미지에서 특정 클래스의 saliency map을 계산하는 방법을 제안한다.
3. gradient-based visualisation 기법이 deconvolutional network 복원 과정을 일반화함을 보여준다.
ConvNet implementation details
- 1.2M training images+labelled into 1000 classes인 ILSVRC-2013 데이터셋을 통해 학습한 하나의 deep ConvNet 활용
https://papers.nips.cc/paper_files/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
ImageNet Classification with Deep Convolutional Neural Networks
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
위의 논문과 아키텍쳐가 비슷하다.
본 논문에서는 추가로 image jittering(이미지의 랜덤한 부분을 0으로 덮어버리는 masking 방식)을 진행하였다. → 모델의 일반화 성능 향상을 위해 했을 것이라고 예상된다.
최종 구조: conv64-conv256- conv256-conv256-conv256-full4096-full4096-full1000 (총 1000개의 클래스이므로 마지막 레이어는 full1000)
ILSVRC-2013 validation set에서 single ConvNet(top-1/top-5 classification error of 40.7%/18.2%)보다 본 논문에서 활용한 모델 네트워크(39.7%/17.7%)가 약간 더 나은 성능을 보였다.
2. Class Model Visualisation
Introduction에서 언급한 본 논문의 첫번째 기여인 ConvNets으로 학습된 class model을 시각화하는 기법에 관한 파트이다.
학습이 완료된 ConvNet과 관심있는 클래스가 주어졌을 때, 해당 클래스에 대해 ConvNet이 가장 높은 점수를 줄만한 이미지를 수치적으로 생성함으로써 시각화한다.
Sc(I)를 이미지 I에 대해 ConvNet이 클래스 c에 할당한 점수라고 하면(이는 softmax이전에 정규화되지 않은 값), L2 규제를 적용하면 아래와 같이 수식을 정리할 수 있다. Sc(I)를 최대화하는 이미지 I를 찾으려고 하면서, 동시에 이미지가 너무 noisy하지 않게 부드럽게 만들어주는 L2 regularization term을 추가한 것이다. 여기서 λ는 regularization 파라미터이다. (L2 regularization 적용하여 weight 구할 때랑 비슷한 식, 다만 여기서는 image를 구하고자 함) 정리하자면, Sc(I)를 최대화하는 L2-regularized된 image를 찾아 생성한다.

이때, back-propagation을 통해 locally-optimal I를 찾을 수 있다. training 과정에서의 back propagation, optimisation과 다른 점은, training 과정에서는 각 레이어의 weight를 최적화하기 위해 back-propagation을 수행하는 것이고, 진행하면서 weight update가 생기는데, 여기서의 optimisation은 이미지 I에 대해 일어나는 것이고 이때 weight는 training 과정에서 학습된 값으로 고정되어있다.
처음에는 0으로 된 이미지에서 최적화를 시작하고, 여기에 mean image를 더해서 class model visualisation 결과를 얻는다.(fig. 1)

Q. 왜 softmax layer를 적용한 class posteriors값 Pc, 즉 Sc에서 정규화를 진행한 값을 사용한게 아니라, raw 값인 Sc를 사용했는가?
A. softmax 확률을 키우려면 다른 클래스 점수를 낮추는 방식으로도 가능하기 때문에 우리의 관심사인 클래스 c에만 집중할 수 없기 때문이다. 즉, softmax 이후 Pc 점수를 최적화하게 되면, 해당 클래스처럼 보이는 이미지를 만드는 것이 아니라 다른 클래스 점수를 낮춤으로써 상대적인 조작이 가능하기 때문에 최적화를 관심사인 클래스 c에만 집중하게 하기 위해 Sc를 최적화하는 방식을 채택하였다.
3. Image-Specific Class Saliency Visualisation
Introduction에서 언급한 본 논문의 두번째 기여인 class saliency map 계산과 관련한 파트이다.
이미지 I0, class c, classification ConvNet with the class score function Sc(I)가 주어졌을 때, 모델이 해당 클래스에 대해 이미지의 어느 부분을 중요하다고 생각했는지 알아내기 위해, Sc(I0)에 미치는 영향을 바탕으로 이미지 I0의 픽셀들을 rank하고자 한다.
클래스 c에 대해 먼저, 간단한 linear score model을 생각해보자.

여기서, w의 각 원소의 크기는 클래스 c에 대해 이미지 I의 각 픽셀들이 가지는 중요도를 정의한다. Image vector I의 각 원소, 즉 pixel들에 weight vector의 각 원소들이 곱해지기 때문이다. (즉, w를 알면 각 픽셀의 중요도를 알수 있으므로 rank할 수 있을 것이다!)
한편, deep ConvNets은 Sc(I)가 non-linear function이다. 위의 선형 모델을 바로 적용하기 힘들다. 하지만, 하나의 고정된 이미지 I0을 기준으로 주변에서만 본다면, first-order Taylor expansion에 의해 Sc(I)를 선형 함수로 근사할 수 있다.
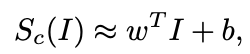
이때, w는 아래와 같이 표현된다.

수식에 의하면, w는 각 픽셀에 대해 이 픽셀을 바꾸면 Sc가 얼마나 바뀌는가를 나타내는 값이라고 해석할 수 있을 것이다.
그런데, 이 논문에서는 또 다른 해석을 제공한다. 바로, w의 크기(gradient의 세기)는, 클래스 점수 Sc에 가장 큰 영향을 주기 위해 "어떤 픽셀이 가장 적게 바뀌어도 되는지"를 나타낸다는 것이다. 이는 위의 수식에서, w는 각 픽셀에 대해 이 픽셀을 얼마나 바꾸면 Sc가 바뀌는 가를 나타내는 값이라는 뜻이다. 조금 더 쉽게 설명하자면, 작게 바뀌어도 Sc를 많이 바꾸는 픽셀들은 해당 클래스 결정에 중요한 역할을 한다는 뜻이므로 모델이 중요하게 본 픽셀이라는 뜻이 된다. 즉, gradient가 큰 픽셀들은 조금만 바뀌어도 Sc에 큰 영향을 미치므로, 대상 object의 위치와 잘 일치할 것이라고 기대할 수 있다.
3.1 Class Saliency Extraction
class saliency map M은 다음과 같이 계산된다.
1. back-propagation을 통해 w를 찾는다.
2. w의 elements를 rearranging함으로써 saliency map을 얻는다.
흑백 이미지와 컬러 이미지의 경우가 다른데, 먼저 흑백 이미지는 채널이 하나이므로 w의 element개수와 이미지 I0의 픽셀 개수가 일치한다. 따라서, saliency map M은 아래와 같이 계산이 가능하다. 이때, h(i,j)는 w의 element의 인덱스로, 이미지 픽셀의 i번째 열, j번째 행에 대응된다.
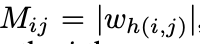
한편, 컬러 이미지와 같은 여러 개의 채널이 존재하는 이미지의 경우, 아래와 같이 계산한다. 이때, c는 컬러 채널이다.
각 픽셀에 대해 모든 컬러 채널 중 가장 큰 w값을 선택한다.

saliency map은 이미지 라벨만으로 학습된 classification ConvNet을 통해 추출되며, object bounding boxes, segmentation masks와 같은 추가적인 annotation 과정이 필요하지 않다. 한번의 back-propagation 과정만 필요하므로 계산이 매우 빠르다.
ILSVRC-2013 test set에서 랜덤하게 선택한 이미지들에 대해 top-1 prediction(가장 높은 점수를 받은 클래스)의 saliency map을 시각화하였다.(fig. 2)

이때, https://papers.nips.cc/paper_files/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html 에서처럼 분류 시 입력 이미지의 10개의 cropped 및 좌우 반전된 버전들을 사용하여 10개의 서브 이미지에 대해 saliency map을 각각 계산해서 평균을 내어 최종 결과로 사용하였다.
3.2 Weakly Supervised Object Localisation
weakly supervised class saliency maps는 주어진 이미지, 클래스에 대해 객체의 대략적인 위치정보를 담고 있기 때문에 object localisation(객체 위치 추정)에 쓸 수 있다.(training 과정에서 이미지 라벨로만 학습하였음에도 불구하고, 즉 학습과정에서 위치정보를 전혀 제공하지 않았음에도) ILSVRC-2013 challenge에서 localisation task를 위해 사용한 간단한 object localisation 과정을 소개하고자 한다.
이미지와 saliency map이 주어지면, GraphCut 기반 colour segmentation을 활용하여 object segmentation mask를 계산한다. 이때 color segmentation을 사용하는 이유는 saliency map이 가장 판별적인 부분만을 포착하므로, 여기에 단순히 threshold를 적용하는 것만으로는 전체 객체를 모두 강조하지 못할 수도 있기 때문이다. 따라서, threshold가 적용된 saliency map을 객체의 다른 부분까지 확장시키는 것이 중요하며, 이를 colour continuity cues(색상 연속성 단서)를 활용해 달성하고자 한다. foreground, background의 색상모델은 Gaussian Mixture Model로 설정되었고, foreground model은 saliency 값이 이미지 내 saliency 분포의 95% 분위수보다 큰 픽셀들로부터 추정되었고, background model은 saliency값이 30% 분위수보다 작은 픽셀들로부터 추정되었다. 그런 다음, publicly available implementation을 통해 GraphCut 분할(segmentation)을 수행하였고, 이미지 픽셀이 foreground와 background로 labeling된 후, object segmentation mask는 foreground pixels중에서 가장 큰 연결 성분(connected component)로 설정된다.(fig. 3)
이 방법은 test set of ILSVRC-2013에서 46.4% top-5 error를 기록하였다. 이 방법에서 주목해야할 점은 weakly supervised + 학습 중에 object localisation task는 전혀 고려되지 않았다는 것이다.

4. Relation to Deconvolutional Networks
Introduction에서 언급한 본 논문의 세번째 기여인 gradient-based visualisation과 DeconvNet architecture간의 커넥션을 확립하고자 하는 파트이다. (앞서 언급된 class model visualisation, image-specific class saliency map은 모두 gradient-based visualisation에 포함된다.)
DeconvNet 기반 n번째 layer input Xn의 복원은, 시각화하고자 하는 뉴런 활성값 f에 대해 Xn에 대한 gradient를 계산하는 것과 유사하다. 따라서, DeconvNet은 실질적으로 ConvNet을 통한 gradient back-propagation과 대응된다.
Xn+1 = Xn*Kn 이 진행되는 convolutional layer의 경우, gradient는 다음과 같이 계산된다.

이렇게 flipped kernel을 이용한 convolution 연산은 DeconvNet에서 n번째 layer의 복원 Rn을 계산하는 것과 일치한다.
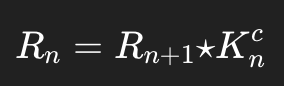
RELU layer Xn+1 = max(Xn, 0)의 경우, sub-gradient는 다음과 같은 형태를 가진다.
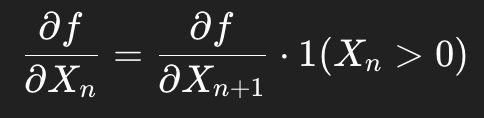
이것은 DeconvNet에서의 RELU 복원과 약간 다른데, DeconvNet에서는 indicator가 Xn이 아니라, 복원된 출력 Rn+1에서 계산된다.

마지막으로, max-pooling layer를 고려해보자.

sub-gradient는 다음과 같이 계산된다.

여기서 argmax는 DeconvNet에서의 max-pooling "switch"와 대응되는데, DeconvNet에서는 max위치를 기억해두고 나중에 복원할 때 해당 위치에만 역전달하기 때문이다.
정리하자면, RELU layer를 제외하면, DeconvNet을 사용해 Rn을 근사 복원하는 것은, back-propagation을 통해 ∂f/∂Xn을 계산하는 것과 동등하며, 후자는 본 논문의 시각화 알고리즘에 포함되는 방식이다. 따라서, gradient-based visualisation은 DeconvNet 방식보다 더 general한 방식으로 볼 수 있다. 왜냐하면, gradient-based 기법은 convolution layer뿐만 아니라 모든 layer의 뉴런 활성화에 시각화를 적용할 수 있기 때문이다. 그 예시로 본 논문에서는 최종 FC-layer의 class score 뉴런을 시각화했다.
참고로, Sect.2의 Class model visualisation은 ConvNet이 기억하고 있는 클래스의 개념을 묘사한 것이며, 특정 이미지에 specific한 것이 아니다. (무에서부터(ex.0으로 된 이미지) 시작해서 Sc를 최대화하도록 입력 이미지를 점차 만들어가는 것이므로, 만들어진 이미지는 어떤 실제 입력 이미지와는 무관하다.) 반면, Sect.3의 class saliency visualisation은 image-specific하다. 즉, 하나의 고정된 입력 이미지에 대해 이 이미지에서 특정 클래스라고 판단하게 만든 픽셀은 어디인가를 시각화하는 것이다. 이미지에 종속된다는 점에서, DeconvNet에서 다룬 이미지 기반 convolution layer visualisation과 유사하다. (본 논문이 가지는 차이점은 convolution layer가 아니라 fully connected layer의 뉴런을 시각화했다는 것이다.)
참고로 계속 언급되고 있는 DeconvNet 관련 논문은 아래와 같다.
https://arxiv.org/abs/1311.2901
Visualizing and Understanding Convolutional Networks
Large Convolutional Network models have recently demonstrated impressive classification performance on the ImageNet benchmark. However there is no clear understanding of why they perform so well, or how they might be improved. In this paper we address both
arxiv.org
Conclusion
본 논문에서 deep classification ConvNets를 위한 두 가지 시각화 기법을 제시하였다. 첫 번째는, 관심있는 클래스를 대표하는 인공 이미지를 생성하는 것이다. 두 번째는, image-specific class saliency map을 계산하는 것으로, 주어진 이미지에서 주어진 클래스에 대해 discriminative한 영역을 강조한다. 우리는 이러한 saliency map이, 별도의 segmentation, detect models를 train하지 않고도 GraphCut-based object segmentation을 초기화하는데 활용될 수 있음을 보였다. 마지막으로, gradient-based visualisation 기법이 DeconvNet 복원 절차를 일반화함을 입증하였다.
향후 연구 방향: 이미지 특이적인 saliency map을 보다 체계적인 방식으로 학습과정에 통합할 계획이다.
📍흐름 정리
ConvNets를 활용한 image classification model의 시각화 기법으로 두 가지를 제시하고 있는데,
첫번째는 ConvNet에 의해 학습된 특정 클래스 개념을 시각화하는 이미지를 생성하는 것. 학습이 완료된 ConvNet과, 관심있는 클래스(ex. 클래스 1)가 주어졌을 때, 클래스 1에 대한 점수를 최대화하는 방향으로 입력 이미지 I를 최적화함으로써, 클래스 개념을 시각적으로 표현하는 인공 이미지를 생성함. 이때, 입력이미지에 무관하게, 클래스 개념을 시각화하는 것임.
두번째는 입력이미지, 주어진 클래스에 대한 class saliency map을 계산하는 것. 이때는 입력이미지에 종속적임. 입력이미지에 대해, 주어진 클래스를 모델이 학습할 때 입력이미지의 어느 부분을 중요하다고 생각했는지를 입력이미지에서 표시하는 map이 class saliency map. 한번의 back propagation을 통해 해당 클래스 점수 Sc에 대한 입력의 gradient, 즉 w를 계산함으로써 salient map 생성.
그리고 첫번째, 두번째 기법이 모두 gradient 기반 방식인데, 이러한 gradient-based ConvNet visualisation 기법이 기존의 DeconvNets 복원 과정과 유사하며, 모든 layer의 뉴런 활성화에 시각화를 적용할 수 있으므로 오히려 더 일반적임을 보임.
추가로, weakly supervised class saliency map은, 학습 과정에서 위치정보를 전혀 제공하지 않았지만, 결과적으로 객체의 대략적인 위치정보를 포함하고 있기 때문에 object localisation task에 활용될 수 있음. saliency map은 모델이 입력이미지를 보고 어떤 영역을 가장 discriminitive하다고 여겼는지를 반영하기 때문에, 직접적으로 위치정보를 제공하지 않았더라도 위치 유추가 가능함. thresholding을 진행하고 foreground, background model을 통해 추정하여 thresholded saliency maps을 계산하고, GraphCut segmentation을 수행하는 과정에서 color continuity cues를 통해 saliency map을 객체의 다른 부분까지 확장한 뒤, 이미지 픽셀을 foreground, background로 라벨링하고 foreground pixels중에서 가장 큰 연결성분을 가진 것들로 object segmentaiton mask를 설정하는 과정을 거침.
'deep learning' 카테고리의 다른 글
| [논문공부] Learning Transferable Visual Models From Natural Language Supervision - CLIP 논문 (0) | 2025.11.18 |
|---|---|
| [논문 공부] Generative Adversarial Nets (0) | 2025.11.03 |
| GPT 구조 이해하기 (0) | 2025.08.11 |
| BERT 구조 이해하기 (2) | 2025.08.08 |

