Geneformer 코드를 살펴보던 중, transformer를 기반으로 한 BERT 모델을 불러온 것을 확인하였다.
Geneformer를 더 잘 이해하려면 BERT 부터 알아야할 것 같다.
Transformer는 공부한 적이 있지만, BERT는 구조를 살펴본 적이 없어서 여기다가 정리해보려고 한다.
BERT: Bidirectional Encoder Representations from Transformers
BERT는 pretrained model.
근본적으로 Language Representation을 해결하기 위해 고안된 구조
즉, 단어, 언어를 어떻게 표현?에 초점을 맞춘 모델
왜 Bidirectional?
문장을 앞->뒤 뿐만 아니라 뒤->앞 으로도 파악하기 위해.
BERT의 기본 구조
Transformer 구조 사용
단, encoder-only model
(아래 그림에서 왼쪽 부분만 사용했다는 뜻. task에 적용이 아니라, 말그대로 '표현'에 필요한 부분만 가져다가 사용한듯)
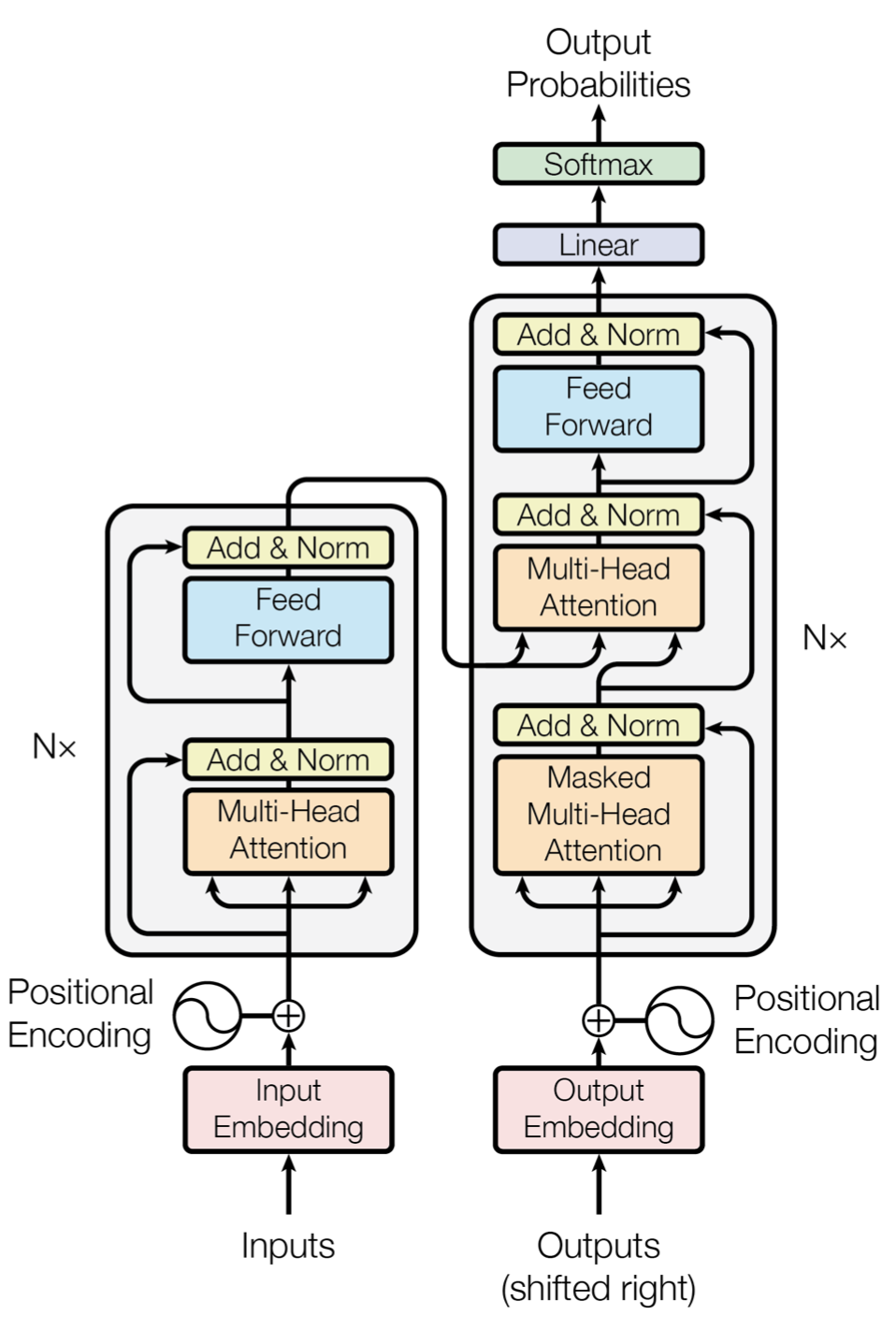
그렇다면 encoder를 어떻게 학습시켰는지 알아보자.
Input Representation

1. Token Embeddings
- 특수 토큰(CLS, SEP)을 사용하여 문장을 구별
- CLS: 입력받은 모든 문장의 시작 토큰; 여기에 classifier를 붙이면 분류 테스크 가능
- SEP: 첫번째, 두번째, 세번째...문장을 구별
2. Segment Embeddings
- token으로 나눠진 단어들을 다시 하나의 문장으로~
- 문장 구별을 하는 임베딩
3. Position Embeddings
- Transformer에서 사용된 것처럼 각 토큰의 위치를 알려주는 임베딩 (but transformer에서 사용한 함수 방법과는 다름)
1,2,3 임베딩을 더한 임베딩이 최종 input으로 사용된다.
Pretraining
두 가지 unsupervised 방식을 사용하여 문장 표현 학습
1. Masked Language Model (MLM)
- 문장에서 단어 일부를 랜덤하게 [MASK] 토큰으로 바꾸고, 이를 Transformer 구조에 넣어서 마스킹된 부분을 예측하도록 학습하는 방식
- 15%를 랜덤하게 [MASK] 토큰으로 바꾸는데, 이 15% 중에서 80%는 [MASK] 토큰으로 바꾸고, 10%는 무작위 단어로 바꿈
-> context 학습 가능
2. Next Sentence Prediction (NSP)
- 두번째 문장이 첫번째 문장의 바로 다음에 오는 문장인지 맞춤
- 라벨은 IsNext / NotNext 두 가지로, 다음에 오는 문장이 맞으면 IsNext, 아니면 NotNext

-> 문장 사이의 관계 학습 가능
cf. pretrained model간 비교
BERT vs OpenAI GPT vs ELMo

위의 그림에서 볼 수 있다싶이 OpenAI GPT, ELMo와 다르게 BERT만 양방향 context 파악 가능
다음에는 Geneformer 코드에서 BERT 불러오는 부분을 다시 살펴볼 예정 (구조 파악)
'deep learning' 카테고리의 다른 글
| [논문공부] Learning Transferable Visual Models From Natural Language Supervision - CLIP 논문 (0) | 2025.11.18 |
|---|---|
| [논문 공부] Generative Adversarial Nets (0) | 2025.11.03 |
| GPT 구조 이해하기 (0) | 2025.08.11 |
| [논문 리뷰] Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps (0) | 2025.05.10 |

