* 논문 정보
제목: Efficient Vision-Language Pre-training by Cluster Masking
저자: Zihao Wei, Zixuan Pan, Andrew Owens
학회명: CVPR
게재연도: 2024
카테고리: multimodal representation, paired VLP, vision masking, MIM(masking image modeling)
Abstract
본 논문은 visual-language contrastive learning에서 학습 속도가 빨라지고 학습된 representation의 quality를 높이는 이미지 패치를 masking하는 간단한 방법을 제안한다. Traning iteration 마다, raw pixel intensities를 기반으로 비슷한 이미지 패치 clusters를 램덤하게 masking한다. 이는 모델이 가려진 이미지의 일부를 오직 주변 문맥(context)만으로 예측할 수 있게 강제한다.(즉, 모델의 문맥 기반 이해 능력이 향상될 것이다.) 또한, 각 이미지별로 데이터 양이 줄어들기 때문에 학습 속도도 빨라진다. 본 논문에서는 다양한 benchmarks를 통해 모델을 평가하였고, 그 결과 기존의 다른 masking 방법들(ex. FLIP)보다 학습된 representation의 quality가 더 좋아진 것을 확인하였다.
1. Introduction
이미지는 많은 redundant information(중복 정보)를 포함하고 있어, 대규모로 효율적인 representation learning을 어렵게 만든다. 최근 연구는 이 문제를 해결하기 위해 vision-language contrastive learning 중에 이미지 패치를 masking하는 방식을 제안했다. 예를 들어, 이미지의 많은 패치를 randomly drop(무작위 제거)하거나, semantically related patches(의미적으로 유사한 패치)를 masking하는 방식이 존재한다. 전자는 연산량과 메모리 사용량을 줄여 학습을 더 효율적으로 만들어주고, 후자는 더 나은 representation을 학습한다는 장점이 있지만 의미적으로 유사한 패치를 묶는 과정이 필요하여 학습과정이 복잡해진다는 단점이 존재한다.
우리는 이러한 단점을 극복한 간단한 masking 방법을 제안한다. 바로, 학습 도중 패치들의 raw RGB 값을 사용하여 clustering을 진행하고, 무작위로 clusters of patches를 masking하는 것이다. 이 방법의 장점은 간단한 visual 유사도 측정만으로도 객체의 일부분과 같은 일관된 시각 구조를 잘 포착할 수 있고, 효율적인 학습이 가능하다는 점이다. 즉 이 방식은 랜덤하게 무작위 제거하는 방식처럼 학습 효율성을 높이면서, 동시에 context 기반 예측을 통해 더 나은 representation learning을 가능하게 한다.

vision-language models에서 널리 사용되는 pre-training task인 masked region classifcation에서 영감을 얻었는데, 이 방식에서는 모델이 object features를 추출하고, 무작위로 가려진 이미지 영역에 대해 해당 객체의 label을 예측하도록 학습한다. 본 논문에서도 이러한 방식과 유사한데, image caption에 라벨들이 포함되어 있기 때문이다.
Conceptual 12M dataset에서 모델 train을 진행하였고, 여러 downstream tasks에서 학습된 representation 평가를 진행하였다. Zero-shot classification(학습 시 보지 못한 클래스에 대해 분류, 이미지를 보고 여러 텍스트 라벨 중에서 하나를 선택), linear probing(사전학습된 feature를 고정하고 그 위에 linear classifer를 학습해서 feature quality평가), text and image retrieval(text->image or image->text), language composition(이미지와 문장의 미묘한 차이(단어, 순서 바꾸기 등)를 구분하는 평가)와 같은 tasks를 포함한다. 실험 결과, 우리의 모델은 효율성을 유지한 채로 FLIP, CLIP보다 나은 성능을 보였다.
2. Related Work
Contrastive Vision-Language Pre-training
Vision-Language Pre-training(VLP)는 이미지와 언어 간 커넥션을 확립하는 데 초점을 맞춘 분야이다. 대표적인 모델인 CLIP은 contrastive learning을 적용하여 올바른 이미지-텍스트 쌍은 가깝게, 틀린 쌍은 멀어지도록 학습한 모델이다. 그러나, 모델을 확장할수록 pre-training의 필요성을 높이고 학습에 필요한 데이터셋 크기와 배치 사이즈가 급격히 증가하는 문제가 발생하였다.
이러한 문제에 대응하여, 최근 연구들은 이미지에 masking을 도입해 학습 시간을 줄이고 배치당 더 많은 샘플을 처리할 수 있도록 시도했다. MaskCLIP, FLIP, VIOLET은 무작위 masking을 적용했는데, 이는 상대적으로 작은 데이터셋에서 효과가 떨어질 수 있음이 확인되었다. 이를 해결하기 위해 ACLIP은 텍스트와의 cross-attention score가 낮은 토큰을 masking하는 방법을 사용했지만 이는 attention map 생성을 위한 두 번의 forward pass가 필요하고 추가적인 계산 모듈도 요구된다는 문제가 있다.
⇒ 본 연구에서는 이러한 한계를 피하고자, 이미지 패치의 raw RGB 값을 기반으로 한 masking 방법을 제안한다.
Masked Image Modeling
language-modeling 분야에서는 가려진(손상된) 입력을 복원하도록 학습하는 모델이 robust feature 생성에 효과적임이 알려져있다. 이러한 접근 방식을 Masked Language Modeling (MLM) 이라고 부르며, 이는 이미지 처리에서도 Masked Image Modeling (MIM) 으로 확장되었다. MIM은 이미지 패치 혹은 그 features를 복원하는 과정을 포함한다. BEIT는 VQ-VAE와 유사하게 discrete token을 복원하는 블록 마스킹 방식을 도입해서 contrastive learning, self-distillation 방식에 필적하는 성능을 보였다. 이후 PeCo는 새로운 visual codebook를 학습하는 방법을, BEIT v2는 teacher-student backbone과 KL divergence loss를 도입한 방법을 제안했다. 최근에는 학습된 features 대신, natural image signals(RGB, HOG(Histogram of Oriented Gradients))를 복원 대상으로 삼는 연구들이 등장했다. 본 논문은 이러한 연구에서 pixel-normalized RGB 값을 유사도 계산에서 사용하는 방식에 영감을 받아, 더 효과적인 patch feature distribution을 구성하고자 하였다.
Masking Strategies in MIM
MIM에서는 masking 전략 자체에 대한 연구도 활발히 이루어졌다.(윗 문단에서는 마스킹 되었다는 가정 하에 어떻게 복원시킬 것인지에 대한 내용이었다면, 이 문단에서는 마스킹 방법 자체에 대한 논의인 것 같다.) 초기 연구들(BEIT 등)은 block-wise masking을 사용하였고, SimMM, MaskFeat, MAE 등은 랜덤한 patch-wise masking을 사용하였다. 그 외에도 Vision Transformer의 attention map을 활용한 attention 기반 masking도 연구되었다. 하지만 이 방법은 충분히 학습되지 않은 attention maps이 구조적 정보를 잘 반영하지 못할 수도 있다는 것이다. SemMAE은 cluster 내의 일부를 먼저 masking하고, 점차 전체 cluster로 masking을 확장해나가는 방식을 채택하였다. Entity-reinforced lagnuage model, EM algorithm을 적용하여 cluster를 생성하고 masking을 수행하는 방식 또한 제안된 바 있다. 우리의 접근 방식 또한 vision-language pre-training에서 cluster based masking 방식을 채택한다. 이는 추가적인 모델의 수정 없이도 pre-training의 속도를 증가시킨다.
3. Method
우리는 contrastive vision-language pre-training에서 cluster based masking strategy를 제안하며, 특히 시각적으로 비슷한 의미를 가진 cluster를 랜덤하게 masking하는 것에 초점을 맞춘다.
1. 먼저 random anchor patches를 cluster centers로 선택하고
2. cluster를 생성하기 위해 pairwise patch distances를 계산한다.
3. 그리고 해당 clusters 전체를 masking한다.
clustering 정확도를 높이기 위해 adaptive layer(거리 계산을 조정하는 모듈)를 도입하고, 배치 내 동일한 입력 사이즈를 보장하기 위해 attention masks(마스킹된 패치가 attention에 포함되지 않게 함), hard patch cutoff(각 이미지에서 남겨야할 최소 패치 수를 강제로 맞춤)를 도입하였다.
3.1. Contrastive Vision-Language Pre-training
우리의 방식은 CLIP과 같은 contrastive VLP방식에 기반한다.
Contrastive learning을 사용하여 올바른 이미지-텍스트 쌍은 가깝게 임베딩을 정렬한다. 이 과정은 두 개의 대칭적인 InfoNCE loss로 이루어져 있다. (vision-to-language loss: Lv->l, language-to-vision loss: Ll->v)

3.2 Cluster Masking
우리는 random clusters를 제거하는 masking 전략을 도입한다. 각 train iteration마다 다른 무작위 clustering 결과를 생성하는 방법을 선택했다. 실험에서는 대안으로 K-Means 기반 clustering을 통한 masking도 평가하였다.
입력 이미지(HxW)를 따라 패치들로 나뉘고, 각 패치는 normalize된 후에 정규화된 패치들의 pairwise cosine similarity를 계산하여 d(x,y) 함수로 사용된다. (이때 유사도는 RGB 값 기반으로 계산하는 것 같다.) 전체 패치 중 5% 미만의 일부를 랜덤하게 선택하여 anchor patches로 지정하고, 각 anchor patch x에 대해 다음 조건을 만족하는 패치 집합, 즉 cluster를 정의한다.

이 cluster 내의 모든 패치는 masking 처리된다. threshold r은 평균 masking 비율에 맞게 training 전에 자동으로 탐색된다.

Clustering Embedding Features
patch feature(패치를 수치적으로 표현한 벡터 느낌?)의 또 다른 특징은 raw RGB 값과 Transformer의 patch embedding layer 특징을 결합한 것이다. 유사도 점수를 계산할 때는 이 두 값을 weighted sum으로 결합하며, 수식은 아래와 같다.

ɑ는 학습이 진행됨에 따라 0에서 1로 선형 증가하는 값이다. (즉, 초기에는 embedding 기반 유사도에 더 의존하고, 후기로 갈수록 RGB기반에 의존)
이 임베딩 레이어는 Transformer 입력 전에 계산되므로, patch embeddings를 추가 연산 없이 Transformer에서 재사용할 수 있다. 또한, positional encoding이 포함되어 있어서 spatial constraints를 도입할 수 있다는 장점이 있다. (단순히 RGB값만 쓰는 것보다 임베딩값을 섞음으로써 의미단위가 추가되고, 비슷한 색을 가진 다른 객체를 구분할 수 있게 된다.)
Handling Batched Inputs
PyTorch와 같은 딥러닝 프레임워크는 uniform input size를 요구하는데, 본 논문의 방법에서는 이미지마다 masking 비율이 달라 패치 수가 달라지는 문제가 존재한다. 이를 해결하기 위해, 각 이미지에 대해 최소 masking 비율 threshold β를 설정하였다. 즉, 어떤 이미지가 이 기준에 미치지 못하면 무작위로 더 많은 패치를 제거하여 기준을 맞춘다. 반대로 masking 비율이 너무 높아서 남은 패치 수가 적은 경우에는, attention mask를 사용하여 masked patches이 attention 계산에 포함되지 않도록 처리한다.
4. Experiments
4.1. Implementation Details
이 논문에서는 Conceptual 12M(CC12M) 데이터셋을 사용해 1,200만 개의 이미지-텍스트 쌍을 기반으로 vision-language 모델을 사전학습했다. Image encoder로는 ViT-B/16을 사용했고, text encoder는 12-layer Transformer로 구성되어 있으며, 8개의 multi-head attention과 512차원의 임베딩을 사용한다. 입력 이미지는 224×224 해상도로 처리되고, 텍스트는 77개의 토큰으로 잘리거나 패딩된다. 클래스 토큰은 MLP(multi-layer perceptron)를 통해 512차원 임베딩으로 변환된다. 학습은 AdamW optimizer를 사용하며, 학습률은 5×10−4, β1=0.9, β2=0.98로 설정하였다. GPU당 배치 사이즈는 256이며, 8개의 NVIDIA A40 GPU를 사용해 모델을 훈련시켰다.
제안된 방법은 총 세 가지 버전으로 구성된다. 첫번째는 K-Means를 이용해 클러스터를 만든 뒤 그 중 절반을 무작위로 마스킹하는 방식이고, 두번째는 RGB 값을 기반으로 유사한 패치를 clustering하여 masking하는 방식, 세번째는 Transformer의 패치 임베딩과 RGB 값을 함께 사용하여 cluster를 생성하는 방식이다. RGB 기반 모델은 평균 마스킹 비율 50% 기준으로 Ours-RGB0.5와 30% 기준의 Ours-RGB0.3으로 나뉘며, 임베딩 모델은 30% masking 비율을 사용한다. RGB 모델은 3%의 패치를 anchor로 선택하고, 임베딩 모델은 5%를 anchor로 사용한다.
비교 실험을 위해 CLIP, FLIP, FLIPAttn 세 가지 baseline을 동일한 CC12M 데이터셋에서 처음부터 학습시켰다. FLIP은 랜덤 마스킹 방식을 사용하며, FLIPAttn은 attention 기반 마스킹(A-CLIP에서 영감을 받은 방식)을 사용한다. FLIP과 FLIPAttn 모두 50%의 패치를 드롭아웃하며, FLIPAttn은 Transformer의 마지막 블록에서 attention score가 높은 패치만 유지한다. 공정한 비교를 위해 모든 모델은 동일한 수의 패치를 사용하도록 조정되었고, 학습률도 모델마다 scaling을 적용해 조절하였다.
모델 성능은 다양한 벤치마크에서 평가되었다. 평가에는 COCO와 Flickr 데이터셋을 활용한 zero-shot image-text retrieval, ImageNet, CIFAR-10, CIFAR-100에서의 zero-shot classification 및 linear probing, 그리고 SUGARCREPE 데이터셋을 이용한 language composition task가 포함된다. SUGARCREPE는 객체, 속성, 관계 단위를 바꾸거나 조합해 만든 유사한 문장을 정답과 구분할 수 있는지를 평가하며, 모델의 문장 조합 이해 능력을 측정한다. 평가 프로토콜은 CLIP 벤치마크의 구현을 따랐다.
4.2. Main Results
Visualization of Clusters
Figure 3에서는 이 masking 기법이 실제로 어떻게 적용되는지를 시각적으로 보여준다. COCO validation set에서 몇 개의 이미지-텍스트 쌍을 무작위로 선택한 뒤, 이미지의 pure RGB 데이터를 기반으로 마스킹을 적용하였다. 시각화는 두 단계로 구성되며, 첫 번째 단계에서는 전체 패치 중 5%를 anchor patch로 무작위 선택하고 이를 붉은색 박스로 표시한다. 두 번째 단계에서는 similarity matrix를 기반으로 계산된 각 cluster를 서로 다른 색으로 나타내어 masking된 영역을 보여준다.

Zero-shot Retrieval Results
모델이 시각적 표현과 언어적 표현 사이의 관계를 얼마나 잘 학습했는지를 평가한다. MS-COCO, Flickr8k, Flickr30k 등의 retrieval benchmark에서 zero-shot image-to-text 및 text-to-image retrieval 성능을 측정하였고, 결과는 Table 1에 제시되어 있다. 특히 image-to-text task에서는 대부분의 데이터셋에서 본 논문에서 제안한 모델이 가장 좋은 성능을 보였으며, 단 하나의 예외는 MS-COCO에서 FLIPAttn보다 약간 낮은 성능을 보인 경우였다. 이와 같은 전반적인 성능 향상은, 주요 객체 중심의 cluster를 우선시하고 노이즈가 많은 영역의 영향을 줄이는 학습 전략 덕분이다.

또한 RGB 정보와 token embedding을 함께 사용하는 방법이 RGB만 사용하는 것보다 더 좋은 성능을 보였으며, 이는 embedding layer가 더 높은 수준의 정보를 포함하고 있기 때문이라고 해석할 수 있다.
FLIP과 CLIP을 비교했을 때, FLIP은 큰 배치 사이즈에도 불구하고 상대적으로 성능이 낮았다. 저자들은 실험 조건에서 FLIP의 장점이 충분히 발휘되지 못했기 때문일 수 있다고 보며, 이는 ACLIP 연구에서도 유사하게 지적된 바 있다. Attention score를 활용한 masking이 random masking보다는 성능이 좋지만, 여전히 cluster-based masking보다는 떨어졌으며, 일부 benchmark에서는 original CLIP보다도 못한 결과를 보이기도 했다.
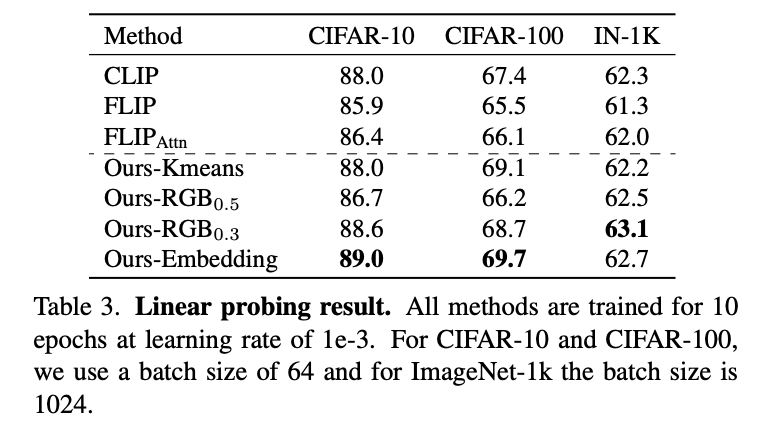
Results on Zero-shot Classification and Linear Probing
먼저, 모델은 여러 잘 알려진 분류 벤치마크에서 평가되었으며, zero-shot classification 결과는 Table 2에, linear probing 결과는 Table 3에 제시되어 있다. 모델들의 훈련 효율성을 더 공정하게 비교하기 위해, 모든 방법의 학습 시간은 CLIP을 기준으로 정규화했으며, CLIP의 학습 시간을 1×로 간주하였다.
CLIP(즉, masking을 사용하지 않은 모델)과 비교했을 때, 제안한 모델은 대부분의 test case에서 더 나은 성능을 보였으며, 평균적으로 +2.1%의 성능 향상과 약 +36%의 훈련 시간 단축을 달성하였다. FLIP과 비교하면, 비슷한 학습 시간을 가졌지만 제안한 모델이 평균 +5.5% 더 우수한 성능을 보였다. FLIPAttn과 비교하면, attention map을 계산할 필요가 없기 때문에 학습 속도가 훨씬 빠르며, 성능 또한 평균 +2.6% 더 높았다.
12개의 zero-shot classification 벤치마크 중, 제안한 RGB 및 embedding 모델은 11개에서 최고 성능을 달성했다. 특히 ImageNet-A, ImageNet-O, ImageNet-R, ImageNet-S와 같은 다양하고 난이도 높은 ImageNet 변형 데이터셋에서도 강력한 성능을 보였다. RGB 기반 모델은 FLIP보다 현저히 높은 성능을 보였고, CLIP도 능가했으며, 이는 단순한 시각적 단서만으로도 본 방법이 효과적임을 보여준다.

Linear probing 결과도 본 모델의 효과를 뒷받침한다. ImageNet에서는 +1.8%, CIFAR-10에서는 +3.1%, CIFAR-100에서는 +4.2%의 정확도 향상을 보였다.
Language Composition
본 논문의 방법의 한 가지 잠재적인 단점은 언어에서 개념들의 구성(composition)을 이해하는 데 어려움이 생길 수 있다는 점이다. 클러스터 단위로 마스킹을 진행하면서, 모델이 단어 간의 관계보다는 단어 자체에만 집중하는 bag-of-words식 경향을 보일 위험이 있다. 예를 들어, 어떤 이미지에 “dog on grass”라는 캡션이 붙어 있을 때, "grass" 영역은 색이 유사한 패치가 많기 때문에 대부분 마스킹될 수 있다. 이 경우, “on”이라는 관계 개념을 학습하는 데 방해가 될 수 있다.
이러한 한계를 검증하고자, 우리는 SUGARCREPE 벤치마크를 활용해 모델의 언어 구성 이해 능력을 평가했다. SUGARCREPE는 문장에서 개념을 추가(add), 교체(replace), 순서 변경(swap)하여 거짓 캡션(negative caption)을 만들고, 원래의 정답 캡션과 구분해내는 retrieval task로 구성되어 있다.
실험 결과는 Table 4에 정리되어 있으며, 관계(Relation) 항목에서는 FLIP과 유사한 수준의 성능을 보였지만, 객체(Object)와 속성(Attribute) 항목에서는 각각 +3.9%, +3.0%의 향상을 보였다. 우리는 이러한 향상이 전체 객체를 마스킹하는 방식 덕분일 수 있다고 본다. 이 방식은 학습 과정에서 시각적 정보의 모호성을 줄여주고, 대조 학습을 더 명확하게 만들어 준다. 이로 인해 모델이 관계나 구성 요소를 더 잘 학습할 수 있었던 것으로 보인다.

Qualitative Comparison of Masking Strategies
Figure 1에서 보이는 바와 같이, 본 논문에서 제안한 마스킹 기법이 random masking보다 시각적으로 중요한 의미 정보(semantic content)를 더 잘 보존한다는 점을 정성적으로 비교하였다. 이 장점은 Figure 7의 captioning 실험을 통해 추가적으로 검증하였다. 이 실험에서는 동일한 이미지를 두 가지 방식으로 마스킹한 후, 각각을 GPT-4 기반 캡셔닝 모델에 입력하여 MS-COCO 스타일의 캡션을 생성하도록 하였다.

실험 결과, 제안한 cluster-based masking 방식은 핵심 요소뿐 아니라 요소들 간의 관계까지 더 잘 유지했다. 예를 들어, 첫 번째 예시에서는 비행기라는 주요 객체를 정확히 인식했으며, 두 번째 예시에서는 야구 선수의 동작까지 잘 기술되었다. 반면, random masking을 적용한 경우에는 이러한 요소나 동작 간 관계가 흐려져, 캡션 품질이 떨어지는 결과를 보였다.
이러한 결과는 우리의 마스킹 기법이 이미지의 내용을 더 정밀하게 이해할 수 있도록 돕는다는 것을 시사한다.
4.3 Ablation Study
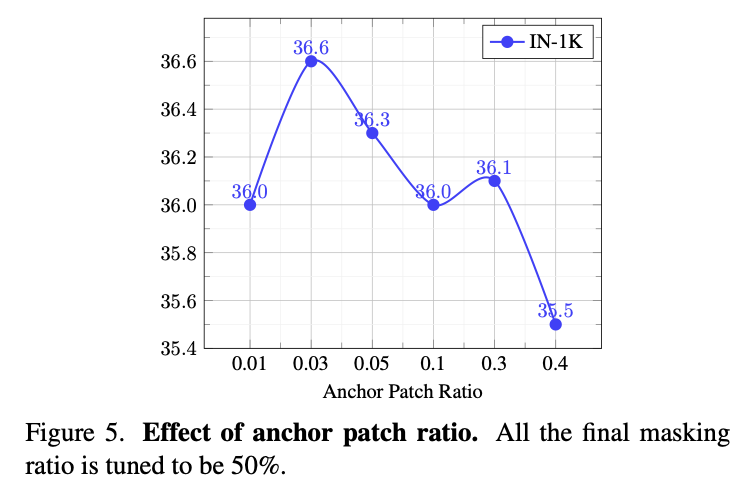
Ablation on Anchor Patch Ratio
모델이 학습한 representation의 품질을 평가하기 위해 ImageNet-1k 데이터셋에서의 zero-shot learning 결과를 벤치마크로 활용하였다. 또한, 각 실험에서 평균 masking ratio가 50%로 유지되도록 threshold를 조정하였다.
실험 결과에 따르면, anchor patch의 비율이 작을수록 더 나은 성능을 보였다. 이는 anchor patch의 선택에서 randomness가 줄어들기 때문에 모델이 학습에 사용할 reference point들이 더 안정적으로 형성되어, clustering 성능이 향상되었기 때문이라고 해석된다. 그러나 anchor patch의 비율이 지나치게 작아지면 similarity threshold 역시 너무 낮아져 clustering 품질이 저하될 수 있기 때문에, 적절한 균형이 필요하다.
Ablation on Minimum Mask Ratio
FLIP 방식과 동일한 평균 마스킹 비율을 갖도록 minimum mask ratio β를 설정하여 우리 방식의 성능을 검증하였다(Table 1, 2, 5 참고). 여기서 우리 방법에서 cutoff ratio는 최소 마스킹 비율을 의미하며, 실제로 모델이 본 patch의 비율은 visible ratio로 나타낸다. FLIP은 모든 이미지에 대해 일정한 마스킹 비율을 유지한다. 실험 결과, 우리 방법은 FLIP보다 더 적은 patch를 보면서도 zero-shot ImageNet-1K 분류 정확도에서 +1.6%의 성능 향상을 보여주었고, 연산 속도도 FLIP과 유사하게 빠르다. attention 기반 masking 방식도 비슷한 성능을 보이지만 연산 속도가 매우 느리다. 이러한 결과는 cluster 기반 masking이 효과적인 denoising 기법 역할을 한다는 것을 시사한다. 이는 모델이 배경처럼 정보가 적고 caption 단어와 관련 없는 영역(예: 단색 배경)을 쉽게 masking할 수 있게 하여, 더 의미 있는 이미지 콘텐츠에 집중할 수 있도록 해주기 때문이다.
또한, 무작위 마스킹의 비율을 줄였을 때 모델의 feature 학습 성능이 향상되는 것도 관찰되었다. cutoff ratio를 50%에서 30%로 줄이자 분류 정확도가 1% 향상되었는데, 이는 성능과 속도 간의 trade-off가 존재함을 보여준다. 그럼에도 불구하고, 높은 마스킹 비율을 유지하는 우리 모델은 여전히 attention 기반 마스킹이나 기존 CLIP보다 훨씬 빠르다.

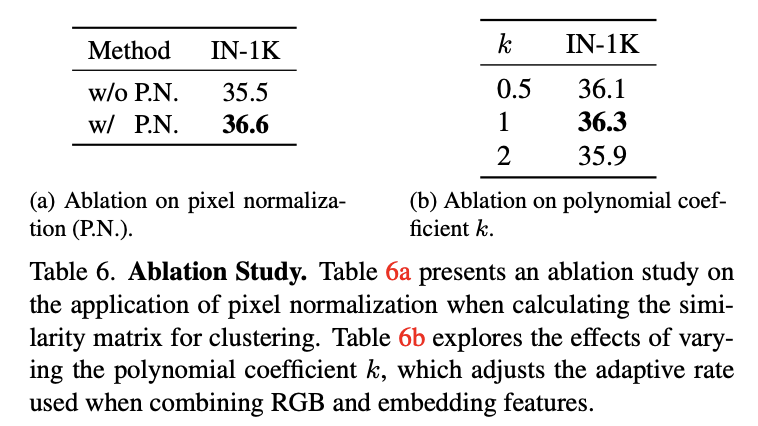
Ablation on Pixel Normalization
이미지 간 similarity matrix를 계산할 때 각 patch의 평균을 0, 표준편차를 1로 정규화하는 pixel normalization 기법을 도입하였다. 그 결과, Table 6a에 나타난 바와 같이 모델의 성능이 +1.1% 향상되었다.
이 성능 향상의 주요 이유는 이미지 patch들을 표준화(standardization)함으로써 각 patch 내의 상대적인 픽셀 강도에 집중할 수 있게 되었기 때문이다. 즉, 이미지 간 밝기 차이로 인한 영향을 줄여 보다 안정적인 비교가 가능해진다.
특히, patch들 간에 pixel intensity의 dynamic range 차이가 클 때 이 정규화가 더욱 유용하다. pixel normalization은 높은 intensity 값을 가진 patch가 비교 과정에서 과도한 영향을 미치는 것을 방지하고, 모든 patch를 공통된 스케일로 조정함으로써 보다 균형 잡힌 유사도 비교를 가능하게 하여 모델이 patch 간의 유사성을 더 정확히 학습하도록 돕는다.
Effect of Features used in Clustering
Clustering에 사용된 Feature의 효과에 대한 분석에서, Tables 1과 2에 따르면 embedding 기반 방법이 RGB만 사용하는 방법보다 뛰어난 성능을 보였으며, 이는 특히 image-to-text retrieval task에서 두드러진다. 그 이유 중 하나는 embedding 모델은 positional encoding 정보를 활용할 수 있는 반면, RGB 기반 모델은 단순히 각 patch의 색상 정보만 활용하기 때문이다. Figure 6은 이를 질적으로 보여준다. 예를 들어, RGB만 사용하는 방식은 색상이 비슷하다는 이유로 머리카락, 그림자, 혹은 노트북과 휴대폰 같은 의도하지 않은 영역까지 마스킹하는 반면, embedding 기반 방식은 보다 일관된 객체 단위의 마스킹을 수행한다.

Ablation on Adaptive Rate
Adaptive Rate에 대한 Ablation에서는 RGB feature와 patch embedding layer feature를 조합할 때, α라는 계수를 통해 두 feature 간 가중치를 조정하였다. 이 계수는 epoch마다 변하며, 현재 epoch을 Ec, 전체 epoch 수를 Et라고 할 때, α는 아래와 같이 정의된다.

여기서 k=1일 경우는 선형(linear) 조합이며, 다른 다항식 계수 k 값들도 실험에 포함되었다(Table 6b 참고).
결과적으로, 선형 방식이 가장 효과적이었는데, 이는 feature 간 가중치 변화가 부드럽고 점진적으로 진행되어 embedding feature로 자연스럽게 전이되기 때문으로 보인다.
4.4. Limitations
본 연구에서는 모든 이미지에 대해 동일한 threshold를 사용하는 방식을 택하였다. 이 방식이 효과적이긴 하지만, 최적의 방식은 아닐 수 있으며, 향후 연구에서는 이미지마다 개별적으로 threshold를 조정하는 adaptive masking 전략이 성능을 더욱 향상시킬 수 있을 것이다.
또한, 본 연구는 ViT-B/16 backbone을 기반으로 하고, CC12M 데이터셋만을 활용하여 학습을 진행하였다. 따라서 실험 범위를 더 다양한 아키텍처와 데이터셋으로 확장한다면 추가적인 인사이트를 얻을 수 있을 것이다.
5. Conclusion
본 연구에서는 cluster 기반의 새로운 masking 전략을 vision-language pretraining을 위해 제안하였다. RGB 값이나 patch embedding layer의 shallow feature를 기반으로 이미지 patch들을 클러스터링한 후, 해당 클러스터들을 무작위로 마스킹함으로써 효율적인 학습이 가능하도록 설계되었다. 이 방식은 이미지 분류 같은 단일 모달 태스크뿐 아니라, 이미지-텍스트 retrieval, 언어 생성 평가 등 다양한 멀티모달 태스크에서 우수한 성능을 입증하였다.
논문 링크
'캡스톤디자인' 카테고리의 다른 글
| 수요예측을 위한 머신러닝, 딥러닝 모델 (0) | 2025.05.21 |
|---|---|
| 요약 (0) | 2025.05.21 |
| 보조 데이터 분석 및 전처리 (0) | 2025.05.21 |
| 메인 데이터 분석 및 전처리 (0) | 2025.05.21 |
| [논문 리뷰] Deep Multimodal Learning with Missing Modality: A Survey (0) | 2025.05.11 |



