* 논문 정보
제목: Deep Multimodal Learning with Missing Modality: A Survey
저자: Renjie Wu, Hu Wang, Hsiang-Ting Chen, Gustavo Carneiro
학회명: ACM Computing Surveys
게재일: September 2024
카테고리: missing modality in multimodal learning
* 키워드
누락된 모달리티 관련 리뷰논문
1. Introduction~4. Methodologies in Strategy Design Aspect 는 기존 여러 논문들을 카테고리에 따라 정리한 부분.
5. 부터 새로운 taxanomy가 등장하므로 아래에는 5부터 정리함.
Abstract
일부 modalities가 존재하지 않아도, model를 rubust하게 만듦으로써 missing modalities 문제를 완화하고자 하는 multimodal learning 기법들이 등장하였고, 이를 Multimodal Learning with Missing Modality (MLMM) 이라고 한다. 본 논문에서는 motivation, MLMM과 standard multimodal learning과의 차이, current methods, applications, datasets, challenges, future directions에 대해 다루고 있다.
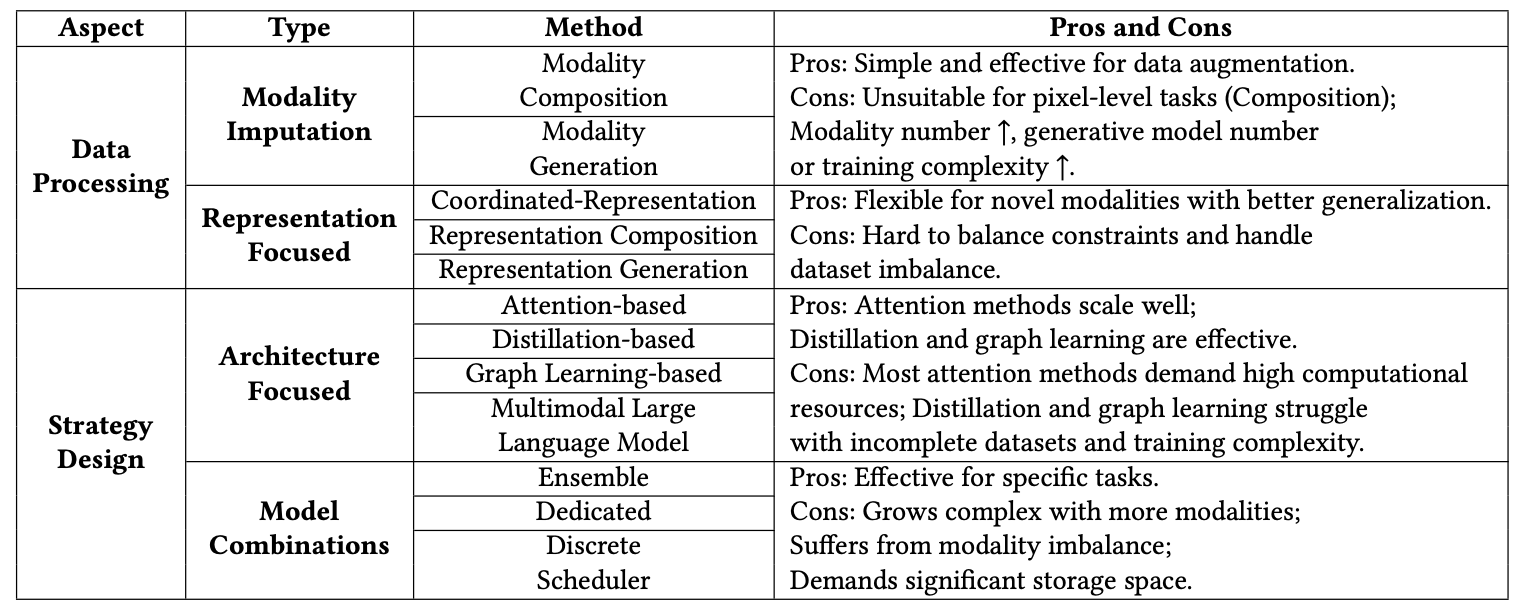
5. Methodology Discussion
Generative and distillation method은 쉽게 구현이 가능하고 성능도 좋기 때문에 가장 일반적인 방법이다.
Transformers methods 또한 larger receptive fields와 parallelism으로 인해 점점 많이 사용되고 있다.
하지만, indirect-to-task generation methods와 대부분의 distillation methods는 불완전한 training datasets을 다루기에는 현재 불가능하다. 아래는 앞의 12개의 methods를 two aspects, four types로 정리하였다.
5.1 Data Processing Aspect
(1) Modality Imputation
1. Modality Composition methods
- combine existing data samples
- fill missing data
단점: pixel-level downstream tasks에는 좋지 않음, available modalities에 대한 의존↑
2. Modality Generation methods
- generative models를 통해 missing modalities를 synthesize
단점: full-modality sample에 접근 가능 여부, 개수에 영향을 받음, training complexity↑, generative models를 위한 추가 storage 필요
(2) Representation Focused
1. Coordinated-representation methods
- allow novel modalities to be introduced by simply adding corresponding branches
단점: constraints, modalities수가 증가할수록 balancing하는 것이 어려움
2. Correlation-driven methods
- 단점: 불완전한 데이터셋으로 pre-training하는 것에 주로 활용되기 때문에 test 환경에서 missing modality 문제 다루기 어려움
3. Representation Composition methods
- available modality representations를 합쳐서 missing modality representations를 복구하려는 시도
- tends to yield better results (∵representations가 modality data보다 더 generalized information을 담고 있음)
4. Representation Generation methods
- modalities간의 관계에 기반하여 represenation 생성
주의)
if..데이터셋이 missing modality samples를 포함한다면
indirect-to-task represenation generation methods는 실현 불가능
if..데이터셋이 심각하게 불균형한 modality 조합을 가지고 있다면
generation methods 또한 이미 존재하는 modalities에 의존적이므로 실패할 것
5.2 Strategy Design Aspect
(1) Architecture Focused
1. Attention-based methods
- 효율적으로 모달리티간 관계를 포착 가능
- scalable in terms of data size
- highly parallelizable
단점: multimodal transformers를 학습시키는 것은 시간이 많이 들고, 많은 GPU 리소스를 요구함
최근, PEL methods(parameter effecient learning)가 이러한 단점을 완화하고 있지만, 이 경우 일반화 성능이 좋지 않음
2. Distillation-based methods
- 구현이 쉬움; student models가 teacher models로부터 inter-modal relationships, 어떻게 missing modality representations을 복원하는지를 배움
- teacher model은 full-modality sampels를 input으로 받아야하므로, complete datasets이 필요함
- intermediate distillation method, self-distillation method..
3. Graph learning-based methods
- intra-, inter-modal relationships를 잘 포착함
단점: 모달리티 수가 증가할수록 복잡도가 커지고 비효율적임, 즉 large-scale datasets에 적합X
4. MLLM
- 임의의 개수의 modalities를 유연하게 다룰 수 있음
단점: training complexity↑, computational resources↑
(2) Model Combinations
- prediction을 위해 여러 모델을 채택하는 방식
1. Ensemble and dedicated training methods
- 데이터셋의 imblanaces in modality combinations에 영향을 받음
- 모달리티 수가 증가할수록 complexity 증가
2. Discrete scheduler methods
- LLM 필요
- 추론 속도 또한 LLMs, modules에 의해 결정
Model Combinations 방법은 전체적으로 많은 model storage를 요구한다는 단점이 존재한다.
5.3 Recovery and Non-Recovery Methods & Some Statistics
MLMM들을 추가적으로 분류하였는데, 이 분류는 초기 단계(early), 중간 단계(intermediate), 후기 단계(late)의 고전적인 멀티모달 학습 분류 체계(classic multimodal learning taxonomy)를 기반으로 한다. 이를 활용하여 recovery and non-recovery methods로 분류하였다. 즉, 결측된 모달리티를 recover하는지 여부에 관한 것이다.
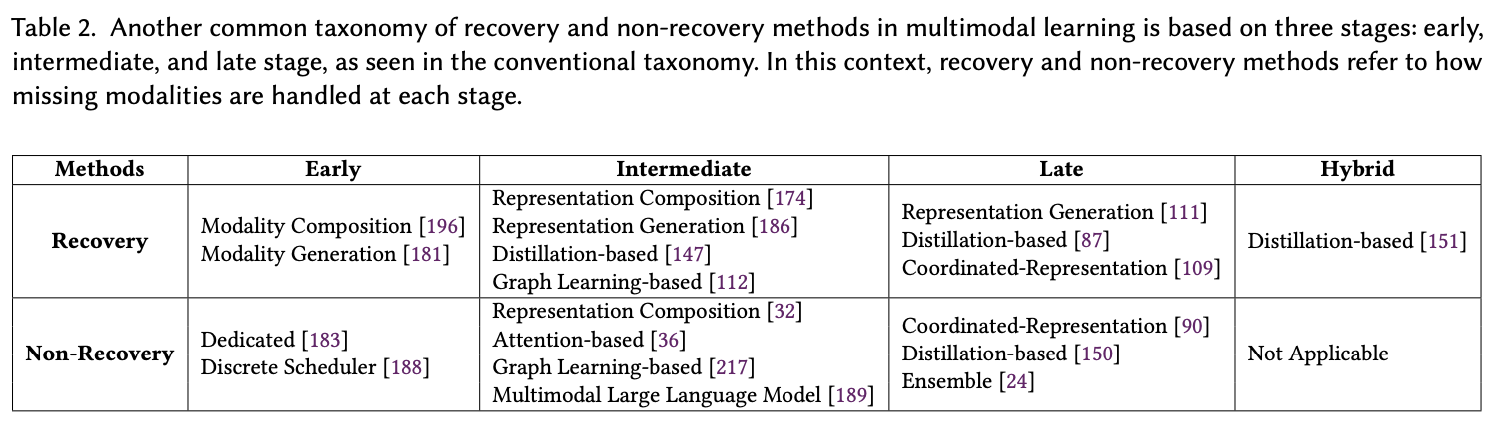
총 315편의 논문을 분석한 결과, 전체의 75.5%가 결측된 모달리티 정보를 복원하는 데 중점을 두고 있으며, 나머지 24.5%만이 복원 없이 추론하는 방법을 탐구하고 있음을 확인하였다.
복원 방식 중에서는:
- 초기 단계 복원 방식이 20.3%
- 중간 단계 복원 방식이 45.8%
- 후기 단계 및 multi-stage 복원 방식이 각각 4.7%
복원을 수행하지 않는(non-recovery) 방식에서는:
- 초기 단계 fusion 방식이 4.2%
- 중간 단계 fusion 방식이 14.1%
- 후기 단계 fusion 방식이 6.3%
중간 단계에서 결측된 모달리티 features을 복원하는 방법이 가장 큰 비율을 차지하고 있다.
이러한 경향은, raw data가 아닌 features을 복원함으로써 불필요한 노이즈와 편향(bias)을 줄이면서, 더 많은 모달리티 특화 정보 또는 공유 정보를 제공할 수 있기 때문이라고 판단된다. 또한, 후기 단계의 특성과 비교했을 때, 중간 단계의 특성은 더 풍부한 표현력을 가지고 있기 때문이기도 하다.
6. Applications and Datasets
MLMM task에서 일반적으로 사용되는 응용 분야별로 데이터셋을 소개한다.
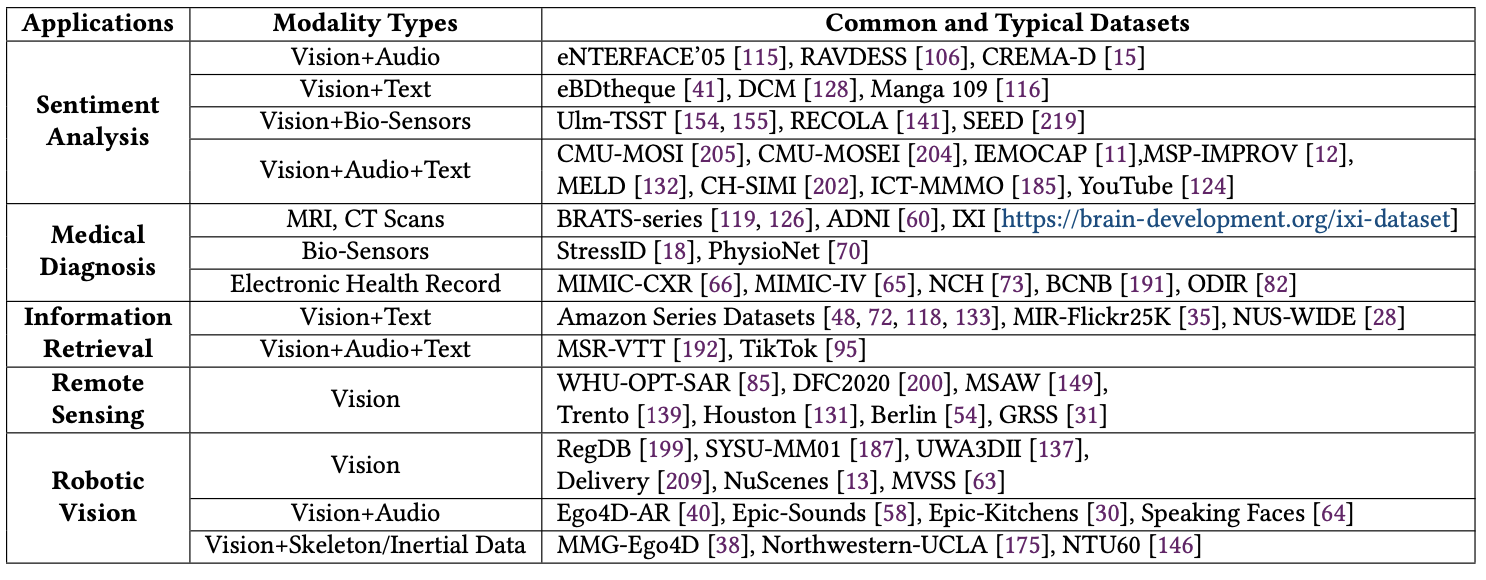
6.1 Sentiment Analysis (감정 분석)
목표: 텍스트, 음성, RGB 영상 등 다양한 모달리티 정보를 결합하여 현재의 감정 상태를 분류
현재 감정분석에 사용되는 데이터셋은 두 가지 유형으로 나뉜다.
1. 비디오, 오디오, 텍스트, 바이오센서 등을 활용하여 실제 상황 또는 영화 속 인간의 감정 상태를 파악하는 데이터셋
2. 텍스트와 이미지를 활용하여 만화 등과 같은 문맥에서 감정 상태를 평가하는 데이터셋
6.2 Medical Diagnosis (의료 진단)
목표: 병력, 신체검사, 이미징 데이터 등 다양한 모달리티에 기반한 종합적인 의료 진단멀티모달 학습의 강점이 발휘될 수 있는 대표적인 분야이다.신경영상 및 뇌질환, 심혈관 질환, 암 진단, 여성 건강 분석, 안과 질환, 수면 장애, 임상 예측, 생의학적 분석 영역 중심으로 데이터셋이 개발되고 있다.
6.3 Information Retrieval (정보 검색)
목표: query(질의어), 사용자 행동 이력, 선호도, 속성 데이터 등을 기반으로 관련 콘텐츠나 데이터를 자동으로 검색알고리즘을 통한 분석과 예측을 통해 사용자가 관심을 가질만한 콘텐츠를 제공함으로써 사용자 만족도와 정보 접근 경험을 향상시킨다.그러나 개인정보 보호 문제, 데이터 부족 문제로 인해 일부 연구자들은 MLMM 접근법을 적용하기 시작했다.많은 연구들은 Amazon, TikTok등 웹사이트로부터 수집한 데이터셋을 활용한다.
6.4 Remote Sensing (원격 탐사)
목표: SAR 데이터, multi-/hyper-spectral data 등 다양한 종류의 시각 정보 통합이러한 데이터셋은 위성이나 항공기를 통해 지구상의 환경 조건, 자원, 재해 등을 평가 및 분석하는 데 활용되고, 환경 보호, 자원 관리, 재해 대응에 큰 도움을 줄 수 있다.
6.5 Robotic Vision (로봇 비전)
목표: 로봇이 시각 센서를 통해 이미지를 수집하고 처리하여 환경을 인지하고 이해하도록 하는 것일반적으로 RGB+X 모달리티 조합을 많이 사용한다. (여기서 X는 LiDAR, 레이더, 적외선 센서, 깊이 센서, 음향 센서 등)
다음은 결측 모달리티 문제와 관련한 롭소 비전의 주요 5가지 task이다.1. 멀티모달 분할: 멀티모달 데이터를 입력받아 관심 객체를 segmentation mask로 추정
2. 멀티모달 객체 탐지: bounding box를 이용하여 관심 객체 탐지
3. 멀티모달 활동 인식: 시각 센서 및 음성 정보를 활용하여 사람의 행동을 인식
4. 멀티모달 사람 재식별: 조명 조건이 다양한 상황에서도 depth 및 열화상 정보를 이용하여 사람 식별
5. 멀티모달 얼굴 anti-spoofing: 다양한 센서를 통해 spoofing 공격 탐지
이 외에도, 아래와 같은 다양한 영역에서 MLMM 기법이 탐색되고 있다.
- 전통적인 audio-visual classifcation, audio-visual question answering, MLLM in visual dialogue, captioning, hand pose estimation using depth images and heat distributions, knowledge graph completion utilizing multimodal data with missing modalities, multimodal time series prediction(ex. 주식 예측), air quality forecasting, multimodal gesture generation on how to create natural animations, multimodal analysis of single-cell data in biology
현재 MLMM 연구는 위에 언급된 5가지 분야에서 활발하게 이루어지고 있다. 특히,
- 비디오·텍스트·오디오 기반 감정 분석에서의 결측 모달리티 처리
- MRI 분할 및 임상 예측
- 자율주행 차량의 다중 센서 의미론적 분할
와 같은 하위 task에 집중되어 있다. 반명, streaming data나 과학 분야에서의 MLMM 연구는 아직 상대적으로 적은 편이다.
또한, 앞서 언급된 대부분의 공개 데이터셋은 모달리티가 완전한 형태이며, 자연스럽게 발생한 결측 모달리티 데이터셋은 매우 드물다.
이로 인해 많은 실험들이 데이터셋 내 기존 모달리티 조합을 바탕으로 다양한 결측 조합을 인위적으로 구성한 후, 결측 비율을 다르게 설정하여 모델을 학습하고 성능을 평가한다. 조사한 논문의 38%가 서로 다른 결측 비율을 조절하여 실험하였고, 62%는 무작위 결측 비율로 실험을 진행하였다. 그리고, 36.4%의 연구가 학습 데이터 자체에서 결측 모달리티를 허용하였고, 63.6%는 test단계에서만 결측 상황을 다루었다.
7. Open Issues and Future Research Directions
7.1 Accurate Missing Modality/Representation Data Generation
많은 연구들은 결측된 모달리티나 그 representation을 복원, 재구성 또는 생성하는 것이 missing modality 상황에서 모델의 성능을 향상시킬 수 있음을 보여주었다. 하지만, 이렇게 생성된 모달리티나 representation은 종종 artifact(왜곡)이나 hallucination(허상)을 포함하며, 이는 생성 모델 자체나 데이터셋의 한계에 의한 것일 수 있다. 따라서, 정확하고 편향되지 않은 결측 모달리티, representation을 생성하는 방법을 탐구하는 것이 중요한 연구 방향이 될 것이다.
7.2 Recovery or Non-Recovery Methods?
현재 대부분의 접근 방식은 결측된 모달 정보를 복원하여 모델이 정상 작동하도록 유도하는 recovery 방법과, 사용가능한 모달리티만으로 예측을 수행하는 non-recovery 방법으로 나뉜다. 하지만 연구에 따르면, 학습 데이터에서 모달리티별 결측 비율이 불균형한 경우, 복원된 정보가 기존 모달리티 정보에 의해 무시되어 결국 모델이 사용가능한 모달리티에만 의존하는 문제가 생긴다. 또한, 중요한 모달리티가 결측되었을 때 모델이 덜 중요한 모달리티 정보에 과도하게 영향을 받는 등과 같은 상황에서는 결측 정보를 recover하는 것이 좋다.
따라서, 언제 복원이 유리한지, 복원된 모달리티가 실제로 기여하고 있는지 아니면 무시되고 있는지 등을 판단하는 것은 중요 과제이다.
7.3 Benchmarking and Evaluations for Missing Modality Problems
현재 많은 연구들이 서로 다른 결측 설정 하에서 학습/테스트되어 있어 동일한 조건에서 성능 비교가 매우 어렵다.
또한 최근 GPT-4와 같은 대형 사전학습 모델의 등장은 시청각 등 다양한 모달리티를 통합한 Multimodal LLM(MLLM) 연구로 확장되고 있지만, 결측 모달리티에 대한 평가 지표나 벤치마크는 아직 부족하다. 따라서, MLLM의 성능을 평가하기 위한 벤치마크가 필요하다.
7.4 Method Efficiency
현존하는 MLMM 방법들은 효율성과 경량성에 대한 고려가 부족하다. 일부 방법은 모달리티 조합마다 독립 모델을 학습해야 하고, 일부 복원 방식은 각 결측 모달리티마다 개별 모델 또는 통합 대형 모델을 사용한다. 이런 방식은 성능은 높지만, 연산 자원이 많이 요구된다. 따라서, 경량화 MLMM 솔루션 개발이 시급하다.
7.5 Multimodal Streaming Data with Missing Modality
현재까지 멀티모달 스트리밍 데이터에서의 결측 모달리티 처리 연구는 매우 제한적이다. 그러나 실제 세계에서는 RGB+X 비디오, 시계열 데이터 등 연속 멀티모달 데이터가 흔하다. 따라서 스트리밍 환경에서의 결측 처리 문제를 해결해야 한다.
7.6 Multimodal Reinforcement Learning with Missing Modality
멀티모달 강화학습(Multimodal RL)은 다양한 센서 정보를 활용하여 로봇 조작, 드론 제어, 자율주행 의사결정 등 다양한 응용에 쓰인다.
하지만 실제 환경에서는 센서 고장이나 데이터 접근 제한 등의 이유로 모달리티 결측 상황이 빈번히 발생하고 알고리즘의 견고함이 약해질 수 있다. 따라서 실제성을 고려한 MLMM-RL 연구의 확장이 필요하다.
7.7 Multimodal AI with Missing Modality for Natural Science
약물 예측, 소재 과학과 같은 과학 분야에서는 분자 구조, 유전체 서열, 분광 이미지 등 이질적인 모달리티의 통합이 핵심이다.
멀티모달 학습은 이를 통해 정확한 예측과 새로운 과학적 통찰을 도출할 수 있다. 하지만 이 분야에서는 데이터 접근 제한, 획득 비용 부담, 모달리티 간 불일치로 인해 결측이 자주 발생한다. 그럼에도 불구하고 과학분야에서 MLMM을 다룬 연구는 아직 매우 부족하므로, 불완전한 멀티모달 데이터를 다룰 수 있는 견고한 모델 개발이 필요하다.
8. Conclusion
이번 서베이에서는 결측 모달리티(Missing Modality) 문제를 다루는 Deep Multimodal Learning에 대한 최초의 종합적 서베이를 제공한다. 먼저, 결측 모달리티 문제가 등장하게 된 동기와, 실제 세계에서 이 문제가 중요한 이유를 간략히 소개한다.
그 후, 우리가 정리한 세분화된 분류 체계(taxonomy)를 바탕으로 현재의 주요 연구 성과를 정리하고, 응용 분야 및 관련 데이터셋들을 검토한다. 마지막으로, 이 분야의 현안 과제들과 향후 연구 방향에 대해 논의한다.
결측 모달리티 문제에 관심을 갖고 연구에 참여하는 연구자들이 점점 늘어나고 있지만, 우리는 여전히 멀티모달 대형 언어 모델 등을 평가하기 위한 통합된 벤치마크의 부재, 자연과학 분야등 응용 범위의 확대 필요성과 같은 긴급히 해결해야 할 문제들에 주목하고 있다.
논문 링크
'캡스톤디자인' 카테고리의 다른 글
| 수요예측을 위한 머신러닝, 딥러닝 모델 (0) | 2025.05.21 |
|---|---|
| 요약 (0) | 2025.05.21 |
| 보조 데이터 분석 및 전처리 (0) | 2025.05.21 |
| 메인 데이터 분석 및 전처리 (0) | 2025.05.21 |
| [논문 리뷰] Efficient Vision-Language Pre-training by Cluster Masking (1) | 2025.05.11 |



