DeepChem의 기본 데이터셋
DeepChem
- 생명과학 분석에 초점을 맞춘 라이브러리
- tensorflow 기반이기 때문에 기존 ML 생태계와 잘 융합됨

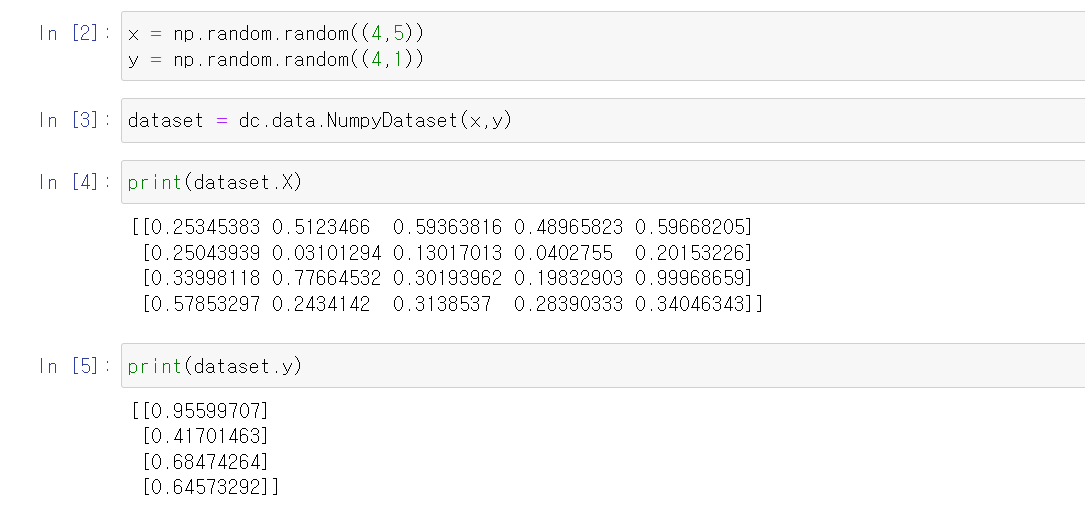
배열의 x축: 각 샘플에 대해 5개의 feature를 갖고 있음
배열의 y축: 각각의 샘플
배열을 NumpyDataset 객체로 저장
독성 분자 예측 모델 만들기
DeepChem의 molnet 모듈 안에 자주 사용되는 데이터셋이 들어있음
이 예제의 경우 Tox21 독성 데이터를 불러옴

tox21_tasks: 각각이 생물학적 target을 나타냄, 각각의 분자와 해당 단백질의 결합력을 나타냄
tox21_datasets: 데이터셋을 불러와 DiskDataset 객체로 만듦, 이렇게 구성하면 데이터셋을 반복해서 불러올 필요가 없음

데이터셋 나누기

train_dataset.X에서 샘플의 수는 6264개이고, 각각의 샘플은 1024개의 feature 값이 있음.
train_dataset.y에서 샘플의 수는 6264개이고, 각각의 샘플에 대해 12개의 데이터포인트(label)이 존재함.
다음으로는, 데이터의 결측치를 확인하여 이러한 결측치를 제외해야 함.

가중치 w
목적1) 누락된 데이터 나타낼 때 사용됨, 가중치가 0이면 해당 label은 손실에 영향을 주지 않으며 학습 중에 무시됨
11521개의 요소는 누락된 측정값(실제 측정된 값이 아님)에 해당하므로 무시함.

transformers 변수는 원본 데이터셋을 수정한 객체
BalancingTransformer 도구가 사용됨. (불균형한 데이터셋을 보완하는 데 사용됨)
왜냐하면, 데이터셋 분자 대부분이 표적에 결합하지 않은 데이터이기 때문에 실제 90%가 넘는 데이터의 label이 0임.
이 경우, 항상 0을 예측하는 모델을 만들면 정확도가 90%라는 뜻.
불균형한 데이터셋을 보완하는 해결책으로 '가중치 행렬 조정'이 있음
BalancingTransformer는 각 클래스에 할당된 총가중치가 동일하도록 개별 데이터 요소의 가중치 요소를 조정함.
=> 한 분류에 대한 선입견을 갖지 않고 학습을 통해 손실 함수의 값을 줄일 수 있음
DeepChem의 models 하위 모듈에는 다양한 생명과학 관련 모델이 포함되어 있음
이 예제에서는 MultitaskClassifier를 사용함.
이는 입력데이터를 통해 여러 가지 예측값을 출력하는 다층 퍼셉트론을 구축하는 모델임 (다중 분류)

n_tasks : 작업 수
n_features : feature 수
layer_sizes : 신경망에 숨겨진 레이어의 개수와 너비를 설정하는 변수
nb_epoch=10 : 한 번의 epoch에 경사하강법 학습을 10번 수행한다는 뜻
(epoch: 데이터셋의 모든 샘플이 학습 알고리즘을 한 번 통과하는 것)
이상적 환경에서는 데이터가 적어지며 최적화된 모델에 도달함, 하지만 실제로는 모델이 학습을 완료하기 전에 학습 데이터가 부족해짐. 따라서 epoch 값을 높여 학습 데이터를 재사용함 (단점: 과적합될 수도 있음)
학습을 마친 모델은 성능을 평가해야하는데, 그에 앞서 먼저 metric(평가 지표)을 정해야함
tox21 데이터셋의 경우 ROC AUC 점수를 사용함.
12개의 분류작업이 존재하므로, 모든 분류 작업의 평균 ROC AUC을 계산해봄. (np.mean 활용)
그 다음, evaluate() 함수를 사용하여 모델 성능을 평가함

train_scores >> test_scores
=> 모델이 과적합되었음
'Bioinformatics' 카테고리의 다른 글
| [논문 리뷰] Divergent projections of the prelimbic cortex mediate autism-and anxiety-like behaviors (0) | 2025.05.09 |
|---|---|
| Vitessce - Views Types (8) | 2025.01.03 |
| Vitessce 정리 (1) | 2025.01.03 |
| [생명과학을 위한 딥러닝] 2장. 딥러닝 소개 (7) | 2024.08.14 |
| [생명과학을 위한 딥러닝] 1장. 왜 생명과학인가? (7) | 2024.08.14 |

