안녕하세요
오늘은 파이썬 환경에서 머신러닝(Machine Learning) 모델을 활용하여 시계열 데이터를 예측하는 방법,
구체적으로는 '수요 예측' 방법 튜토리얼을 작성해보려고 합니다.
시작하기에 앞서,
시계열 데이터가 무엇인지부터 간단하게 언급하고 넘어가겠습니다.
시계열 데이터(time-series data)는 시간의 흐름에 따라 관측값이 순차적으로 기록된 데이터를 말합니다.
쉽게 말해서 "시간에 따라 변하는 값"을 포함하는 데이터를 의미하는데요,
대표적인 예시로 기온 변화 데이터, 주식의 일별 데이터, 제품 판매량 데이터 등이 있습니다.
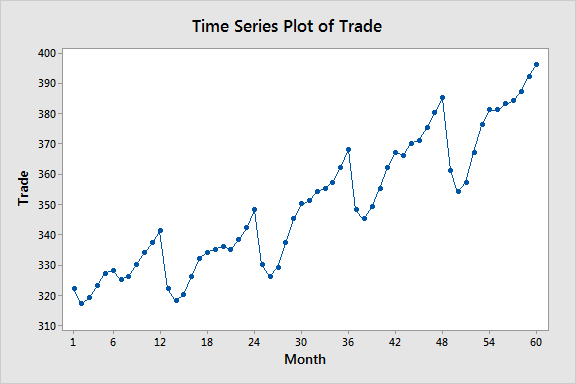
이런 데이터들은 모두 시간 순서가 중요한 대표적인 시계열 데이터입니다.
그 중에서도 이번 글은 베이커리 판매량 데이터를 활용해보려고 합니다.
실제로 빵집에서는 매일매일 상품별로 얼마만큼의 양을 준비해야하는지 발주량을 잘 예측하는 것이 중요합니다.
너무 많이 만들면 폐기 비용이 발생하고, 너무 적게 만들면 품절이 발생해 판매 기회를 놓치게 되니까요.
그만큼 아주 중요한 task인데,
그래서 오늘은 이 데이터를 바탕으로
일자별・상품별 판매량을 머신러닝 모델, 특히 CatBoost로 예측하는 방법을 단계별로 정리해보려고 합니다.
(모델 전체 학습 과정이 아닌, '예측' task 부분에 해당합니다.)
실제 프로젝트는 현업 베이커리 매장에서 수집한 실제 판매 데이터를 기반으로 모델을 개발했습니다.
하지만 보안상의 이슈로 인해 이번 튜토리얼에서는 저희가 내부 검증용 실험에서도 함께 활용했던 Kaggle의 "French Bakery Sales" 데이터셋을 사용해 진행하려고 합니다.
https://www.kaggle.com/datasets/matthieugimbert/french-bakery-daily-sales
French bakery daily sales
Forecast sales for a French bakery
www.kaggle.com
데이터셋이 달라져도 모델링 과정이나 코드 흐름은 비슷하므로,
이 튜토리얼에서 설명하는 작업 흐름은 일반적인 수요 예측 데이터에도 그대로 적용할 수 있습니다.
바로 시작하겠습니다.
0. 파이썬 환경 세팅
이번 글은 파이썬(Python) 환경을 기반으로 진행됩니다.
코드 실행은 Google Colab, Jupyter Notebook, VSCode 등 편하신 환경에서 하시면 됩니다.
파일 형태는 .ipynb(노트북)나 .py(스크립트) 모두 활용 가능합니다.
실행 방법은, .ipynb 파일의 경우 아래 코드들을 한 블럭씩 실행하거나,
.py 파일의 경우 전체 코드 파일을 run을 통해 한번에 실행하면 됩니다.
1. 데이터셋 불러오기 & 전처리

이 load_pos 함수에서는 데이터셋(bakery sales.csv)을 불러와서, 컬럼 이름을 나중에 알아보기 쉽게 한국어로 바꿔주고, type 점검도 진행합니다.
또한, 이후 머신러닝 모델에 입력 시 필요한 컬럼들('날짜', '상품명', '수량')만 남기고 drop하는 과정도 포함합니다.

이제 함수를 통해 데이터셋을 불러오고, 데이터셋의 전체적인 구조를 파악해봤습니다.
이 French Bakery Sales 데이터의 경우 1년 반 정도 되는 데이터이고, 149개의 상품을 포함하고 있는 데이터네요.
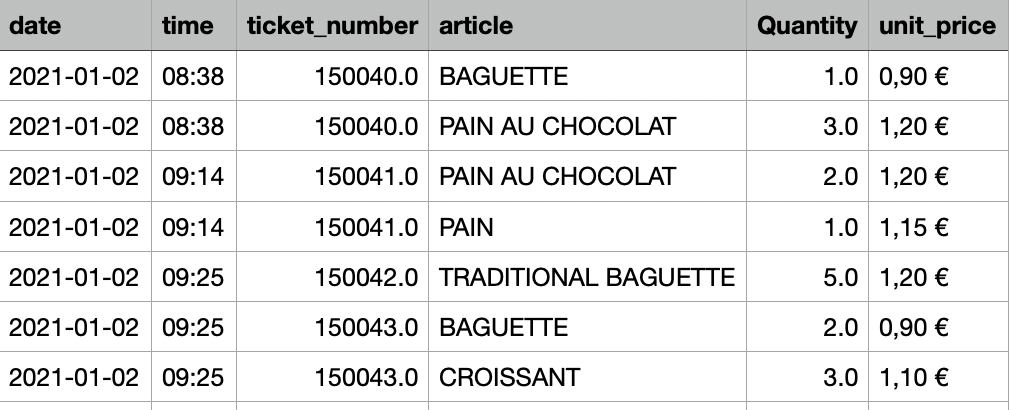
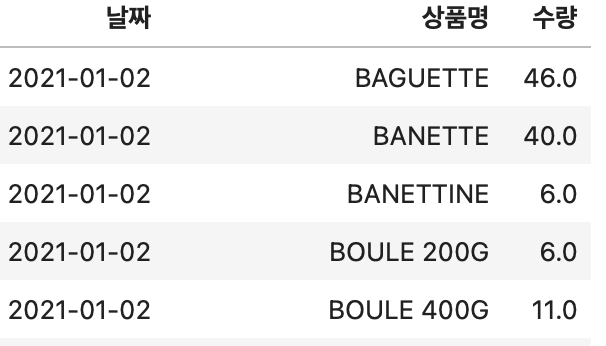
이러한 과정을 통해 원래는 왼쪽과 같았던 데이터셋이, 해당 함수를 거친 후 오른쪽과 같이 변하게 됩니다.
더 깔끔해지고, 필요한 정보들만 남게 된 것을 확인할 수 있습니다.
2. 예측 그리드 생성하기
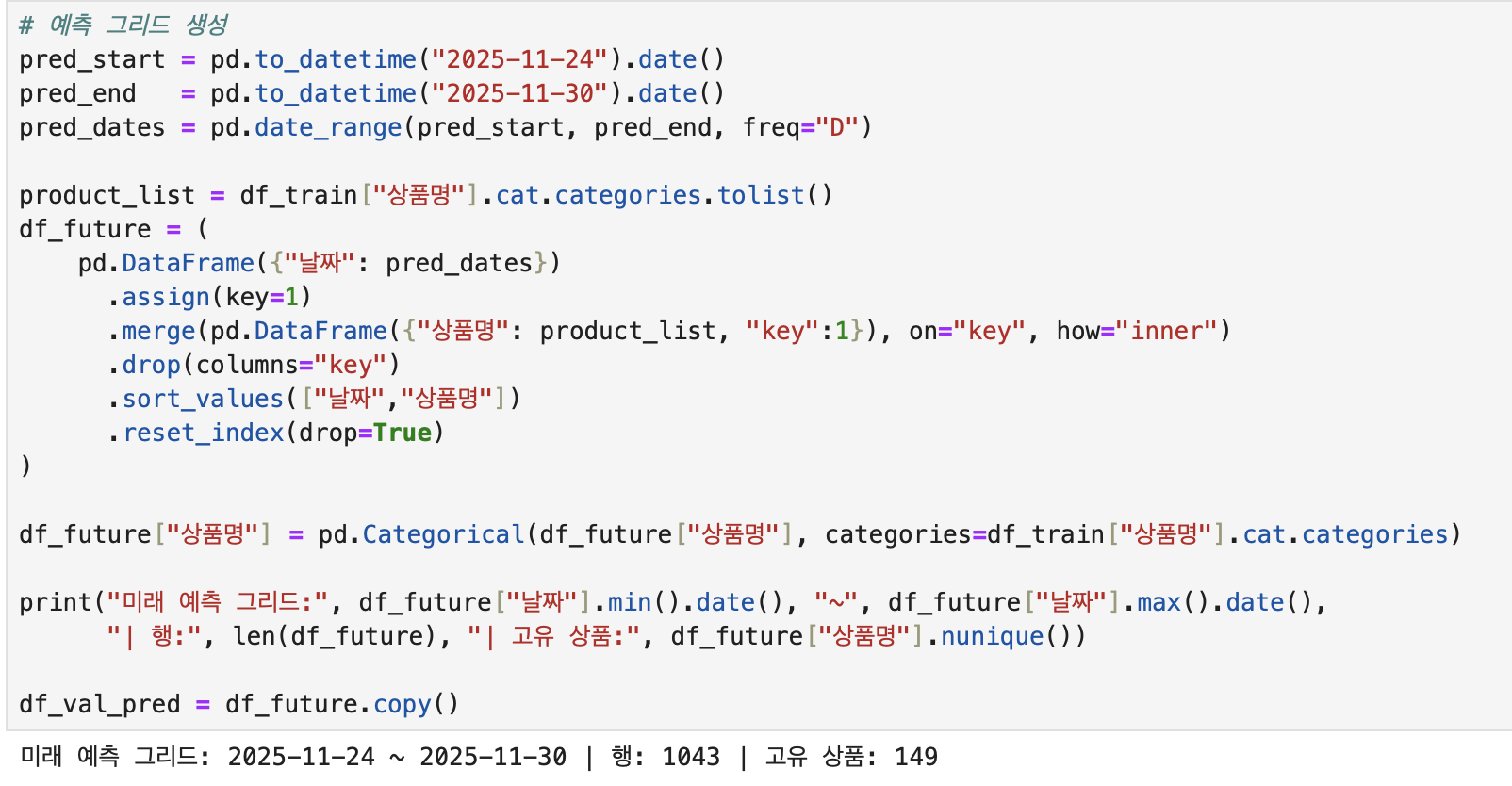
예측 그리드란, "모델이 미래 값을 예측할 수 있도록 입력 형태를 미리 만들어놓은 테이블"입니다.
pred_start, pred_end에 예측하고 싶은 기간의 시작과 끝을 입력하면,
그 기간에 해당하는 빈 테이블이 생성됩니다.
3. 외부 변수 feature 생성 함수 정의

먼저, 'French Bakery Sales' 데이터셋은 프랑스 파리에 위치한 베이커리 데이터셋이기 때문에, 좌표를 프랑스 파리에 맞게 설정해줘야 합니다.
(만약 대한민국 서울에 위치한 데이터셋을 사용하고 싶은 경우, LAT, LON을 서울의 위도, 경도에 맞게 설정하고, TIMEZONE을 'Asia/Seoul'로 설정하면 됩니다.)

이제 본격적으로 외부 변수 함수를 정의합니다.
외부 변수로는 요일, 공휴일, 날씨(기온, 강수량)를 사용할 예정입니다.
- _to_date(): 데이터를 받아 요일을 Monday, Tuesday...와 같은 형식으로 반환하는 함수
- _holiday_dates(): 데이터와 기간을 받아 해당 기간동안 프랑스 공휴일에 해당하는 날짜들을 반환하는 함수
- 만약 대한민국 베이커리 데이터를 활용한다면, holidays.KR 과 같이 국가코드를 변경하면 됩니다.
- build_calendar_features(): _to_date(), _holiday_dates() 함수를 호출하여 실제 데이터에 요일, 공휴일 외부변수를 추가하는 함수
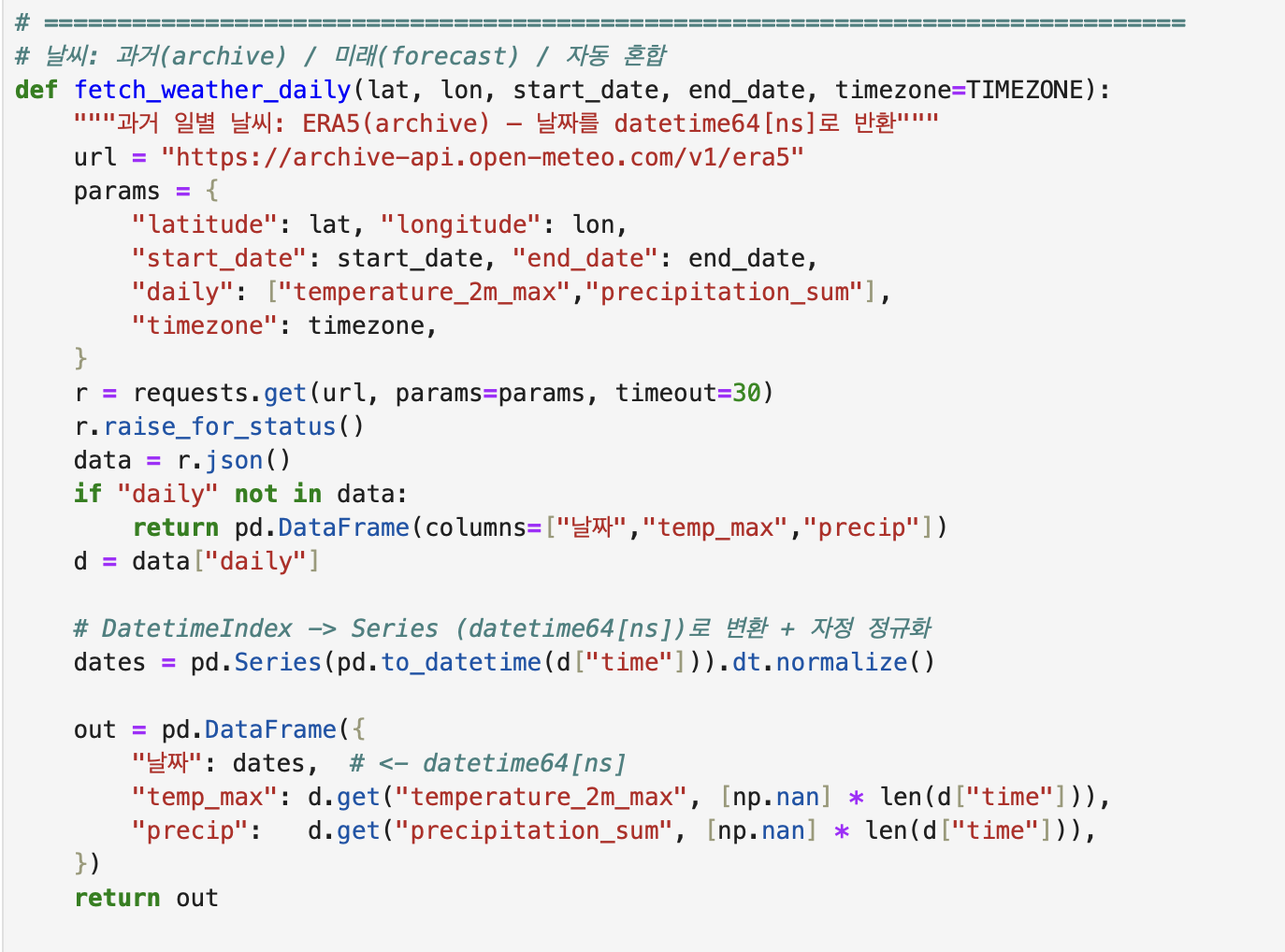
위에서 요일, 공휴일을 추가하였으니, 날씨를 추가하려고 합니다.
Open-Meteo API를 외부에서 호출해서, 데이터셋에서 각 날짜별로 최고 기온 & 강수량 합계를 반환하여 데이터셋에 추가합니다.
🌤️ Free Open-Source Weather API | Open-Meteo.com
We're constantly evolving and expanding. We're dedicated to providing you with the latest features, weather variables, and data sources. If you want to stay in the loop and be the first to know about our exciting updates, we invite you to subscribe to our
open-meteo.com
Open-Meteo API는 누구나 사용가능한 공개 날씨 API입니다!
4. 외부 변수 feature 반영
위에서 외부 변수 관련 함수들을 정의했으니,
이제 실제로 이 함수들을 활용해서 데이터셋에 외부 변수를 추가하는 과정이 필요합니다.

make_features() 함수를 통해 데이터셋에 외부변수를 추가하는 로직을 구현했습니다.
df_train은 지금까지 누적된 모든 판매데이터를 포함한 학습용 데이터이고,
df_val_pred는 앞으로 예측할 기간의 날짜, 상품 정보, 공휴일, 요일, 예측 날씨값을 담은 예측용 데이터입니다.
이 과정을 통해 아래와 같이 외부 변수들이 추가된 데이터셋 구축이 완료되었습니다.
각 날짜, 상품별로 판매 수량, 요일, 달(month), 공휴일 여부, 최고 기온, 강수량 등이 반영된 것을 확인할 수 있습니다.
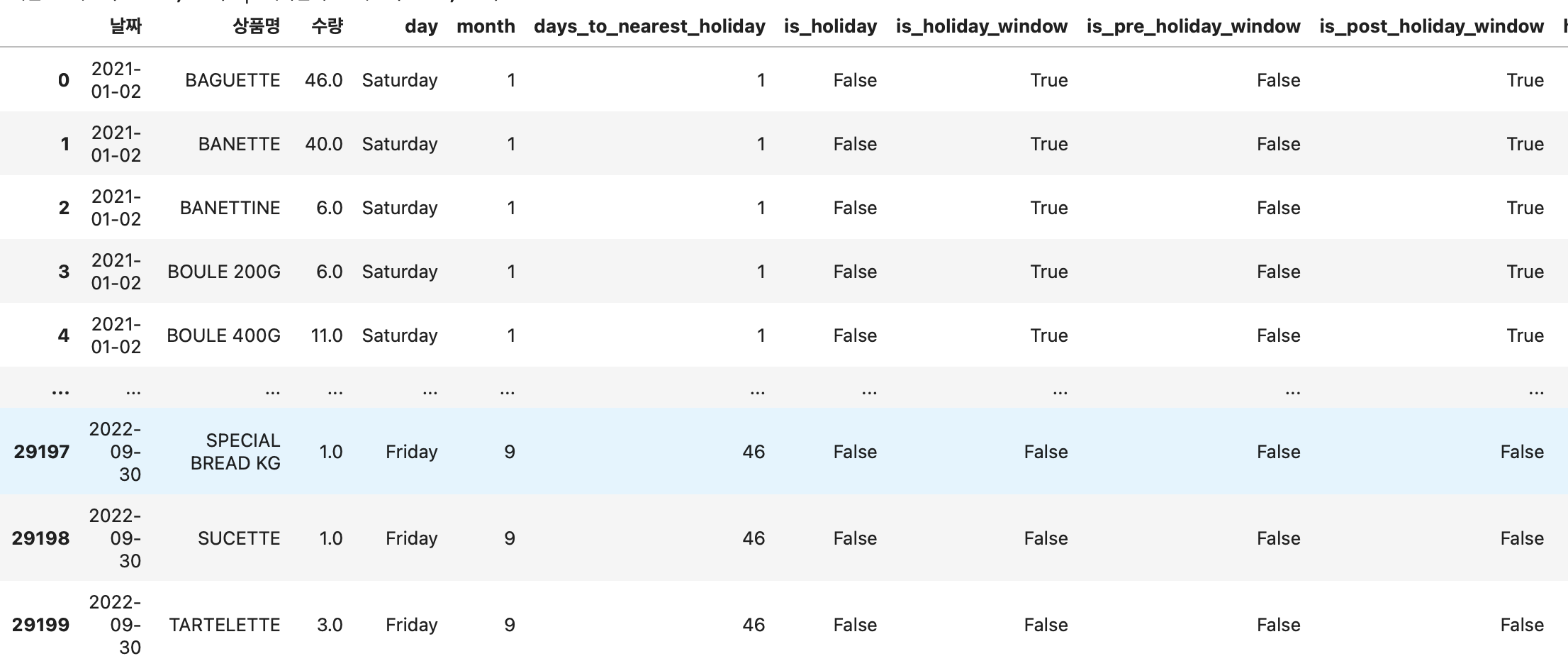

이제 머신러닝 모델에 넣기 위한 데이터셋 준비를 마쳤습니다.
5. CatBoost으로 예측

이제 본격적으로 머신러닝 모델에 데이터를 넣어서 수요 예측을 진행할 차례입니다.
이번 튜토리얼에서는 여러 머신러닝 모델 중에서 CatBoost를 선택했습니다.
물론 XGBoost, LightGBM 등 다른 부스팅 계열 모델을 사용하더라도 전체적인 흐름은 동일합니다.
전체 프로세스는 바뀌지 않기 때문에, 혹시 다른 시계열 데이터로 예측 task를 하고 싶으시다면 상황에 맞게 모델을 바꿔서 적용하셔도 됩니다.
튜토리얼에서는 CatBoost를 사용할 예정이므로, CatBoostRegressor 클래스를 불러와야합니다.

우리 모델의 예측 목표(Target)는 바로 ‘수량’입니다. 따라서 데이터프레임에서 수량 컬럼을 TARGET으로 설정해줍니다.
이제 앞에서 준비한 데이터셋을 TARGET 컬럼 기준으로 나눠서 모델에 입력할 준비를 해야 합니다.
앞 단계에서 외부변수(공휴일, 요일, 날씨)를 데이터에 모두 추가해두었기 때문에,
X_train에는 이러한 feature 컬럼들이 모두 포함됩니다.
y_train은 오직 실제 정답 역할을 하는 '수량' 컬럼만 사용합니다.
이 두 데이터를 활용해 본격적으로 모델을 학습(train)시키게 됩니다.
추가로, 예측 단계에서 사용할 X_pred도 준비해야 합니다.
X_pred는 예측하고자 하는 기간의 feature 테이블로 구성되며, 형태는 X_train과 동일해야 합니다.
이 데이터를 모델에 입력하면, 해당 기간 동안의 예상 판매량을 각 일자별, 상품별로 예측할 수 있습니다.
즉, 여기서 모델은 다양한 외부 변수(요인)를 입력으로 받아, 해당 예측 기간 날짜의 일자별로 수량이 얼마나 팔릴지를 예측하도록 학습하는 구조입니다.

모델 학습 단계에서는 CatBoostRegressor 클래스를 이용해 모델을 정의합니다.
이번 프로젝트에서는 R² 점수를 주요 평가지표로 사용했고, learning_rate, iterations 등 핵심 하이퍼파라미터는 여러 차례의 반복 실험을 통해 얻은 최적값으로 설정했습니다.
이제 준비된 X_train, y_train을 활용해 model.fit()을 실행하면 본격적인 학습이 진행됩니다.
학습이 끝난 뒤에는 성능을 빠르게 점검하기 위해 R², MAE, RMSE 세 가지 지표를 출력해보았습니다.
모델이 데이터를 얼마나 잘 따라가고 있는지, 그리고 실제 수량과 비교했을 때 오차가 어느 정도인지 확인하기 위한 과정입니다.

그 결과, Train 세트 기준 R²는 약 0.9374,
MAE는 3.23, RMSE는 8.71로 확인되었습니다.
즉, 모델이 전체 변동성의 약 93%를 설명하며 비교적 안정적으로 수량을 예측하고 있음을 알 수 있습니다.
학습이 완료된 모델을 사용해 model.predict()를 호출하면, 예측하고자 하는 기간의 예측 수량 결과를 얻을 수 있습니다.
이때 예측 결과는 날짜, 상품명, 그리고 예상 수량을 담은 df_out 데이터프레임입니다.
마지막으로, 이 결과를 사용자가 원하는 경로인 OUT_PATH에 CSV 파일로 저장합니다.
6. 결과 확인
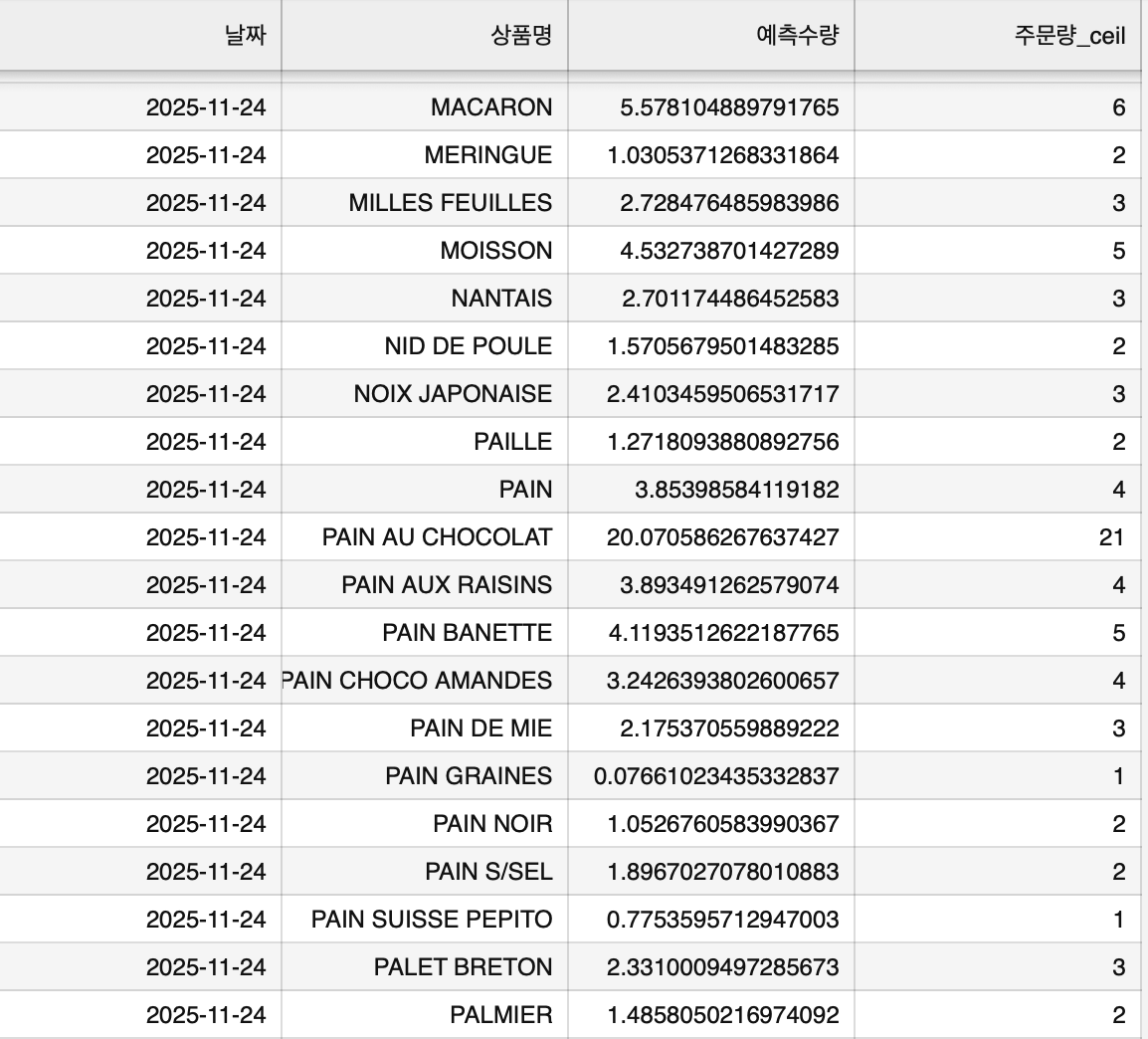
머신러닝 모델 실행 후 생성된 CatBoost_prediction.csv 파일을 열어보면,
각 날짜별, 상품별 모델이 예측한 수량과 함께, 추천 발주량(주문량_ceil)이 포함되어 있습니다.
추천 발주량은 예측 수량을 올림(ceil)처리한 값입니다.
그 이유는 대부분의 베이커리에서 품절로 인한 손실이, 남은 재고로 인한 폐기 비용보다 크기 때문입니다.
즉, 예측 수량보다 한 개라도 더 준비하는 것이 실무에서 손익 측면에서 안전한 선택이라고 생각하여 이렇게 처리하였습니다.
(필요에 따라, 폐기 비용이 높은 상품은 올림 대신 버림(floor)이나 반올림(round)을 적용하는 것도 가능합니다.)
마무리하기 전에,
궁금해하실만한 질문에 대해 두 가지 답변하고 마무리하려고 합니다.
Q. 왜 전통적인 시계열 모델이 아니라 머신러닝(ML)을 사용하나요?
ARIMA, SARIMAX, Prophet과 같은 전통적 시계열 모델들은 이미 시계열 데이터에서 잘 동작한다고 검증된 바가 있습니다.
하지만, 실제 판매 데이터의 경우 요일 효과, 공휴일 효과, 날씨 효과, 이벤트 영향 등의 여러 비선형적 패턴들이 발생합니다.
이러한 패턴들은 선형 패턴을 잘 포착하는 전통 시계열 모델들로 캡쳐하기가 쉽지 않습니다.
따라서 이번 튜토리얼에서는 풍부한 feature(요일, 날씨, 이벤트 등)를 쉽게 반영하기 위해 머신러닝 모델을 활용하였습니다.
Q. LSTM, Transformer와 같이 시계열 데이터 예측에 좋은 성능을 보일 것이라고 생각하는 딥러닝 모델은 왜 사용하지 않았나요?
사실 딥러닝 모델도 이미 적용해보았지만, 머신러닝 모델에 비해 성능이 좋지 않고, 학습 속도도 훨씬 오래 걸렸기 때문에 머신러닝 모델로 최종 결정하였습니다.
왜 딥러닝 모델이 본 튜토리얼의 데이터에서 잘 동작하지 않을까..라고 분석을 해보자면,
가장 큰 이유는 데이터가 충분히 크지 않기 때문일 것 같습니다.
딥러닝 모델은 데이터가 많아야 잘 동작하는데,
이번 튜토리얼에서 활용한 데이터의 경우 약 1년반 치 데이터이기 때문에 데이터 수가 많지 않습니다.
따라서 머신러닝 모델이 딥러닝 모델보다 성능이 좋은 것이라고 추측할 수 있고,
딥러닝 모델이 잘 동작하기 위해서는 최소 3~5년치 데이터가 있어야할 것이라고 예상하고 있습니다.
또한 참고로, 이 튜토리얼은 train/validation/test의 과정, 즉 머신러닝 모델을 학습하는 과정을 전부 담은 게 아니라,
실제 상황에서 필요한 task인 "예측"만 수행하는 과정만 담았습니다.
즉 운영 환경에서 Predict-only 코드 과정을 보여주는 것이기 때문에, 이미 내부에서 충분히 검증된 모델을 기반으로
"전체 과거 데이터 모두 학습 → 미래 기간 예측" 방식을 보여드린 것입니다.
여기까지 따라오셨다면, 이제 어떠한 시계열 데이터라도 머신러닝 모델을 적용하여 예측할 수 있는 기본적인 파이프라인을 익히신 겁니다.
데이터 준비, 외부 변수 추가, 외부 변수 feature로 반영, 그리고 예측용 그리드 구성, 머신러닝 모델로 예측까지 경험하신 거니까요!
읽어주셔서 감사합니다 :)

'캡스톤디자인' 카테고리의 다른 글
| 딥러닝 모델: TFT, DeepAR, N-BEATS (2) | 2025.07.08 |
|---|---|
| 수요예측을 위한 머신러닝, 딥러닝 모델 (0) | 2025.05.21 |
| 요약 (0) | 2025.05.21 |
| 보조 데이터 분석 및 전처리 (0) | 2025.05.21 |
| 메인 데이터 분석 및 전처리 (0) | 2025.05.21 |


